유한모집단의 모수 계산
$$ \begin{align} 평균 \quad & \mu = \frac{\sum X_{i}}{N} \\ 분산 \quad & \sigma^{2} = \frac{\sum (X_{i} - \mu)^{2}}{N} \\ 표준편차 \quad & \sigma = \sqrt {\sigma^{2}} = \sqrt {\frac{\sum (X_{i} - \mu)^{2}}{N}} \\ \end{align} $$무한모집단의 모수 계산
$$ \begin{align} 평균 \quad & \mu = E(X) = \sum X_{i}P_{i} \\ 분산 \quad & \sigma^{2} = Var(X) = \sum [X_{i} - E(X)]^{2} \cdot P(X_{i}) \\ 표준편차 \quad & \sigma = \sqrt{\sigma^{2}} =\sqrt{\sum [X_{i} - E(X)]^{2} \cdot P(X_{i})} \\ \end{align} $$통계량 계산
$$ \begin{align} 평균 \quad & \bar{X} = \frac{\sum X_{i}}{n} \\ 분산 \quad & S^{2} = \frac{\sum (X_{i} - \bar{X})^{2}}{n-1} \\ 표준편차 \quad & S = \sqrt {S^{2}} = \sqrt {\frac{\sum (X_{i} - \bar{X})^{2}}{n-1}} \\ \end{align} $$증명 $$ \begin{align} E(S^{2}) &= E \left[ \frac{1}{N} \sum(X_{i}-\bar{X})^{2}) \right]\\ &= E \left[ \frac{1}{N} \sum \{ (X_{i}-\mu)-(\bar{X}-\mu) \}^{2} \right]\\ &= E \left[ \frac{1}{N} \sum \{ (X_{i}-\mu)^{2} - 2(X_{i}-\mu)(\bar{X}-\mu) + (\bar{X}-\mu)^{2} \} \right] \\ &= E \left[ \frac{1}{N} \sum(X_{i}-\mu)^{2} \right] -2E \left[ \frac{1}{N} \sum(X_{i}-\mu)(\bar{X}-\mu) \right] + E \left[ \frac{1}{N} \sum(\bar{X}-\mu)^{2} \right] \\ \end{align} $$
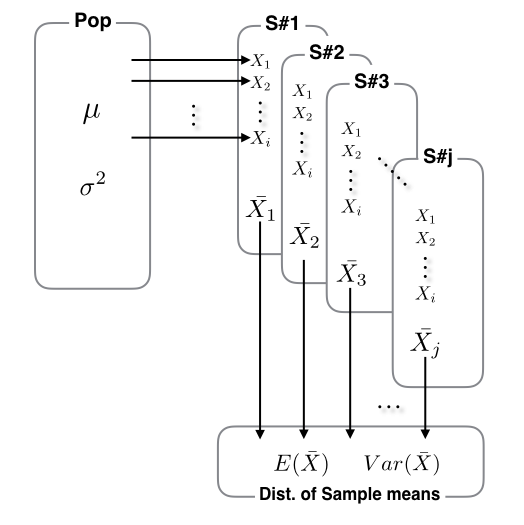
<img src="https://github.com/JKeun/lecture-statistics/blob/develop/%20img/Distribution-of-Sample-Means.png?raw=true", width=400>
ex. 어느 상자에 90, 60, 30 이라고 쓰여진 카드 3장이 있다. 이 세 장의 카드 중에서 한 장씩 두 장을 표본으로 뽑을 때, 그 표본들의 평균의 분포양상을 알아보자. (복원추출)
| $X_{i}$ | 확률 $P(X_{i})$ |
|---|---|
| 90 | 1/3 |
| 60 | 1/3 |
| 30 | 1/3 |
위의 모집단에서 표본크기 $n=2$로 표본을 뽑을 때의 가능한 모든 표본과 이들 표본의 평균은 ?
| 가능한 표본 | 표본의 평균 $(\bar{X_{i}})$ |
|---|---|
| 90, 90 | $\bar{X_{1}} : 90$ |
| 90, 60 | $\bar{X_{2}} : 75$ |
| 90, 30 | $\bar{X_{3}} : 60$ |
| 60, 90 | $\bar{X_{4}} : 75$ |
| 60, 60 | $\bar{X_{5}} : 60$ |
| 60, 30 | $\bar{X_{6}} : 45$ |
| 30, 90 | $\bar{X_{7}} : 60$ |
| 30, 60 | $\bar{X_{8}} : 45$ |
| 30, 30 | $\bar{X_{9}} : 30$ |
| $\bar{X_{i}}$ | 확률 $P(\bar{X_{i}})$ |
|---|---|
| 30 | 1/9 |
| 45 | 2/9 |
| 60 | 3/9 |
| 75 | 2/9 |
| 90 | 1/9 |
$$ \mu_{\bar{X}} = \sum \bar{X_{i}} \cdot P(\bar{X_{i}}) = 30 \times \frac{1}{9} + 45 \times \frac{2}{9} + 60 \times \frac{3}{9} + 75 \times \frac{2}{9} + 90 \times \frac{1}{9} = 60 $$위의 식을 이용하여 위의 표에 제시된 평균의 표집분포의 기댓값을 계산해보자.
평균의 표집분포의 평균과 모집단의 평균의 관계 $$ 평균 \quad \mu_{\bar{X}} = \mu $$
증명 $$ \begin{align} \mu_{\bar{X}} = E(\bar{X}) &= E \left[ \frac{1}{N} \sum X_{i} \right] \\ &= \frac{1}{N} \left[ E(X_{1}) + E(X_{2}) + \cdots + E(X_{N}) \right] , \quad ( X_{1}, X_{2}, \cdots X_{N} 은 벡터)\\ &= \frac{1}{N} \cdot N \cdot E(X) \\ &= E(X) = \mu \end{align} $$
$$ 모분산 \quad \sigma^{2} = (90-60)^{2} \times \frac{1}{3} + (60-60)^{2} \times \frac{1}{3} + (30-60)^{2} \times \frac{1}{3} = 600 $$$$ 표본평균의 분산 \quad \sigma_{\bar{X}}^{2} = (30-60)^{2} \times \frac{1}{9} + (45-60)^{2} \times \frac{1}{9} + (60-60)^{2} \times \frac{3}{9} + (75-60)^{2} \times \frac{2}{9} + (90-60)^{2} \times \frac{1}{9} = 300 $$위의 식을 이용하여 모집단의 분산과 표본평균의 분산을 계산해보자.
평균의 표집분포의 분산(표준편차)과 모집단의 분산(표준편차)의 관계 $$ 분산 \quad \sigma_{\bar{X}}^{2} = \frac{\sigma^{2}}{n} \\ 표준편차 \quad \sigma_{\bar{X}} = \frac{\sigma}{\sqrt{n}} $$
증명 $$ \begin{align} Var(\bar{X}) &= Var \left[ \frac{1}{N} \sum X_{i} \right] \\ &= (\frac{1}{N})^{2} \cdot \sum Var(X_{i}) \\ &= \frac{1}{N^{2}} \left[ Var(X_{1}) + Var(X_{2}) + \cdots + Var(X_{N}) \right] , \quad ( X_{1}, X_{2}, \cdots X_{N} 은 벡터) \\ &= \frac{1}{N^{2}} \cdot N \cdot Var(X) \\ &= \frac{Var(X)}{N} = \frac{\sigma^{2}}{N} \end{align} $$
모집단이 정규분포일 때
모집단이 정규분포가 아닐 때
중심극한정리 (Central Limit Theorem)
<img src="https://upload.wikimedia.org/wikipedia/commons/1/12/Central_Limit_Theorem.png", width=600 >
$\chi^{2}$분포(chi-square distribution)
{kind=link}
{kind=link}
{kind=link}