: 최빈값은 빈도수가 가장 많이 발생한 괄찰값을 말함
: 중앙값은 수치로 된 자료를 크기순서대로 나열할 때, 가장 가운데에 위치하는 관찰값을 말한다.
: 우리가 흔히 사용하는 간단한 평균, 그냥 "평균" 이라고도 한다.
$$\bar{X} = \frac{X_1 + X_2 + \cdots + X_n}{n} = \frac{\sum X_i}{n} $$: 같은 모집단에서 표본을 서로 다른 개수로 뽑은 경우(가중치가 존재하는 경우) 평균값을 구할때 사용
$$\bar{X} = \frac{n_1 \bar{X_1} + n_2 \bar{X_2} + \cdots + n_k \bar{X_k}}{n_1 + n_2 + \cdots + n_k} = \frac{\sum n_i \bar{X_i}}{n_i} $$1. 여집합
2. 합집합
3. 교집합
합집합의 계산
사전에 알고 있는 정보에 기준을 두고, 어떤 사건이 일어나게 될 확률을 계산하는 이론 <img src="https://wikimedia.org/api/rest_v1/media/math/render/svg/2b35567a9a29e146c9426f9b258892d1df6bb789", width=200, height=200>
Extended form <img src="https://wikimedia.org/api/rest_v1/media/math/render/svg/935f9eb7f8d17e5c166ef2e8bd6a94366b32fa7c", width=200, height=200>
<img src="https://wikimedia.org/api/rest_v1/media/math/render/svg/2b8c21165bcf1ad1d21d7047686d227c649aae16", width=250, height=250>
기댓값의 계산 $$ E(X) = \Sigma X_{i} \cdot P(X_{i}) $$
기댓값의 특성
표준편차의 계산 <br > $$ \sigma_{X} = \sqrt { \Sigma[X_{i} - E(X)]^{2} \cdot P(X_{i}) } $$
분산과 표준편차의 특성
This can also be expressed as
<img src="https://wikimedia.org/api/rest_v1/media/math/render/svg/a7523b2ddba75e02e1afe1ba4f5f9f7599305585", >
<img src="http://www.ktword.co.kr/img_data/1995_4.JPG", width=160>
<img src="http://cfile3.uf.tistory.com/image/2613DE42543252631267AE", width=380>
<img src="http://cfile222.uf.daum.net/attach/241D0435555BF3BE087948", width=500>
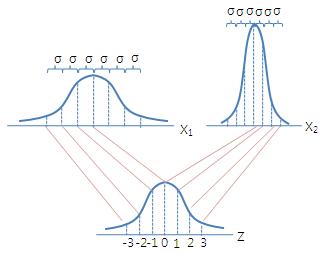
$Z$-통계량 $$ Z = \frac{(\bar{X} - \mu_{\bar{X}})}{\sigma_{\bar{X}}}$$
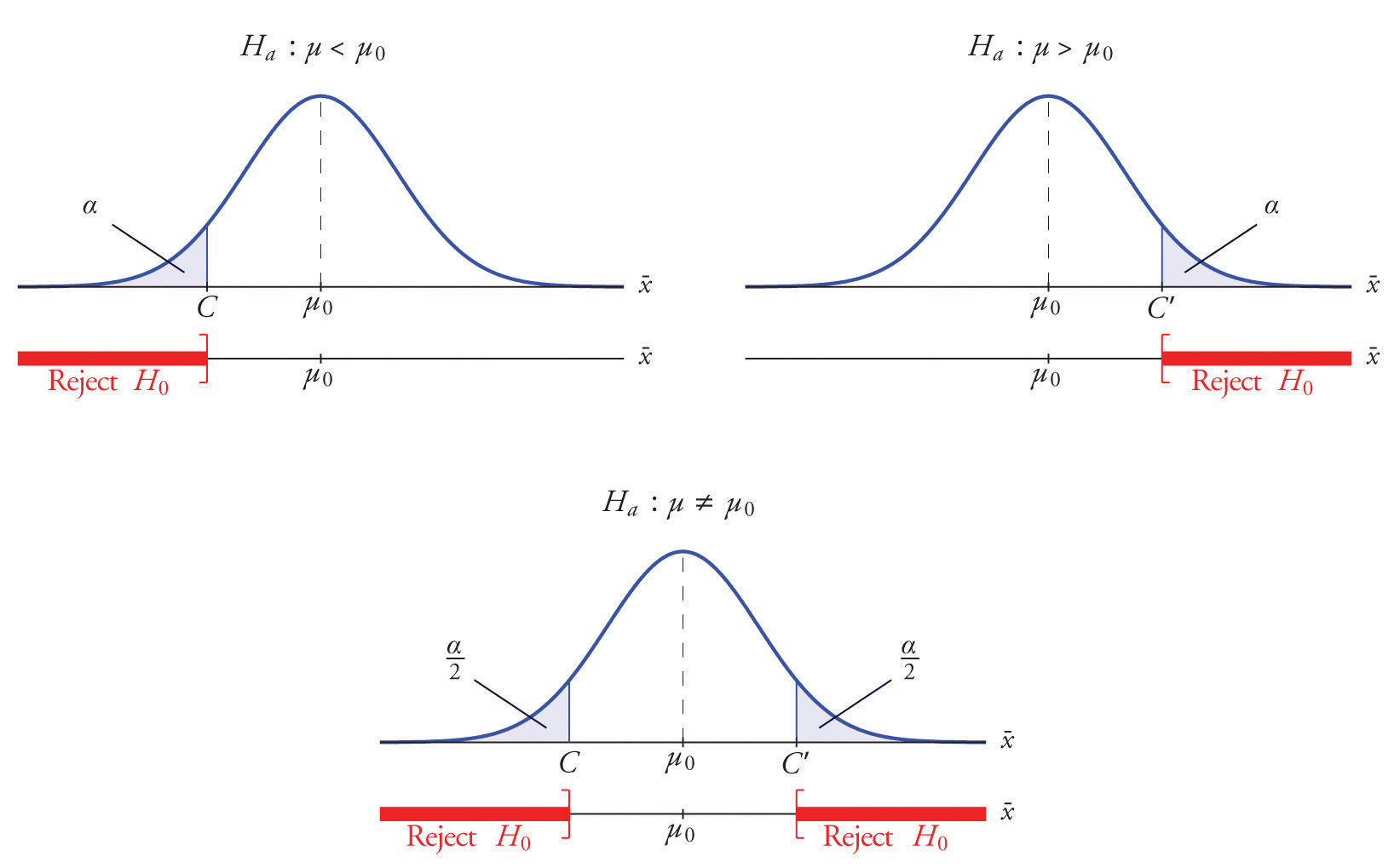
$Z$ 값에 대한 신뢰구간 $$ P(-Z_{\alpha /2} \le Z \le Z_{\alpha/2}) = 1 - \alpha $$
$\mu$ 값에 대한 신뢰구간
$$
P(\bar{X} - Z_{\alpha /2} \cdot \sigma_{\bar{X}} \le \mu \le \bar{X} + Z_{\alpha/2} \cdot \sigma_{\bar{X}} ) = 1 - \alpha
$$
| 신뢰도 $(1-\alpha)$ | $Z=0$에서 $Z_{\alpha /2}$까지 면적 | $Z_{\alpha / 2}$ |
|---|---|---|
| 0.90 | 0.450 | 1.64 |
| 0.95 | 0.475 | 1.96 |
| 0.99 | 0.495 | 2.57 |
<img src="https://saylordotorg.github.io/text_introductory-statistics/section_12/72f0cd42fda04cdfb0341bcfe11601c1.jpg", width=800>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}