<br > <img src="https://upload.wikimedia.org/wikipedia/commons/thumb/9/96/Uniform_Distribution_PDF_SVG.svg/500px-Uniform_Distribution_PDF_SVG.svg.png", width=350>
정규분포의 확률밀도함수(pdf)
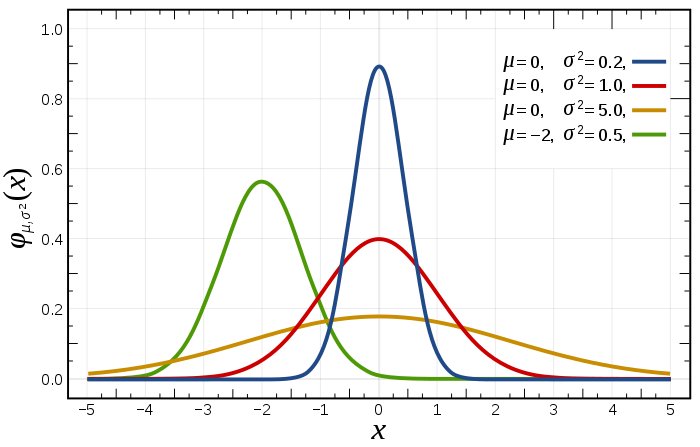
<br > <img src="https://upload.wikimedia.org/wikipedia/commons/thumb/7/74/Normal_Distribution_PDF.svg/700px-Normal_Distribution_PDF.svg.png", width=450>
정규분포의 특성
ex. 어느 학생이 영어와 수학 시험을 치렀다. 그 결과 영어점수는 80점이고 수학점수는 75점이었 다. 이 학생은 어느과목을 더 잘했다고 할 수 있는가?
ex. 추가정보 : 영어과목에서는 전체학급의 평균은 90점, 표준편차는 5점 그리고 수학과목에서는 평균이 60점, 표준편차가 10점이라고 한다.
In [1]:
import numpy as np
import scipy.stats as sp
import matplotlib.pylab as plt
mu1 = 90; mu2 = 60; std1 = 5; std2 = 10
rv1 = sp.norm(mu1, std1); rv2 = sp.norm(mu2, std2)
In [2]:
xx1 = np.linspace(70, 110, 100); xx2 = np.linspace(30, 90, 100)
fig = plt.figure(figsize=(8, 3))
plt.subplot(1, 2, 1)
plt.plot(xx1, rv1.pdf(xx1))
plt.title("English")
plt.xticks([70, 80, 90, 100, 110])
plt.ylim(0)
plt.scatter(90, 0, color='blue', linewidths=5)
plt.scatter(80, 0, color='red', linewidths=10)
plt.annotate("80", xy=(80, 0), xytext=(80, 0.01),
arrowprops=dict(facecolor="black", linewidth=0.5),
fontsize=15
)
plt.subplot(1, 2, 2)
plt.plot(xx2, rv2.pdf(xx2))
plt.title("Math")
plt.xticks([40, 50, 60, 70, 80])
plt.ylim(0)
plt.scatter(60, 0, color='blue', linewidths=5)
plt.scatter(75, 0, color='red', linewidths=10)
plt.annotate("75", xy=(75, 0), xytext=(75, 0.005),
arrowprops=dict(facecolor="black", linewidth=0.5),
fontsize=15
)
plt.show()
이처럼 개인의 각 과목점수($X$)는 각 과목의 평균과 표준편차를 동시에 비교해야만 더욱 의미있는 해석을 할 수 있다. 즉, $X$가 각 분포에서 어떤 위치에 있느냐를 살펴보고 분석할 수 있다.
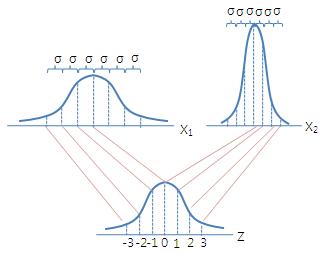
표준정규분포
앞에서 든 예를 $Z$의 척도로 바꾸어 보면, $$ 영어 \quad Z = \frac{80 - 90}{5} = -2, \quad 수학 \quad Z = \frac{75 - 60}{10} = 1.5 $$
<img src="http://www.ktword.co.kr/img_data/1995_4.JPG", width=250>
<img src="https://cdn.namuwikiusercontent.com/b0/b041d8f0f6deec5bf96dba163cbc15829001a17560e6de6d37a7038d4ada20d7.jpg?e=1488320568&k=EI1Jbm7rpfTmw3ifSPF69Q", width=380>
Q. 예제
$Z=0$부터 $Z=1.5$ 사이에 확률변수가 있을 확률 <br > $P(0 \le Z \le 1.5) = 0.4332$
$Z=-1$부터 $Z=1$ 사이에 확률변수가 있을 확률 <br > $P(-1 \le Z \le 0) + P(0 \le Z \le 1) = 2 \times 0.3413 = 0.6826 $
$Z=-1.5$부터 $Z = -0.5$ 사이에 확률변수가 있을 확률 <br > $P(0 \le Z \le 1.5) - P(0 \le Z \le 0.5) = 0.4332 - 0.1915 = 0.0.2417 $
$Z=-2$보다 작거나 $Z = 2$ 보다 큰 사이에 확률변수가 있을 확률 <br > $P( Z \le -2) + P( Z \ge 2) = 2 \times ( 0.5 - 0.4772) = 0.0456 $
Q. 연습문제
한 초등학교 전교생의 IQ를 측정해 본 결과 평균 $\mu = 100$, 표준편차 $\sigma = 10$ 이었다. 이 초등학교 학생들의 IQ 분포가 정규분포를 이룬다고 가정할 때, IQ가 100에서 110사이인 학생의 비율은 얼마나 될까?
In [3]:
import numpy as np
import scipy.stats as sp
import matplotlib.pylab as plt
from matplotlib.patches import Polygon
mu1 = 100; mu2 = 0; std1 = 10; std2 = 1
rv1 = sp.norm(mu1, std1); rv2 = sp.norm(mu2, std2)
xx1 = np.linspace(70, 130, 100); xx2 = np.linspace(-3, 3, 100)
fig = plt.figure()
ax1 = fig.add_subplot(211)
plt.plot(xx1, rv1.pdf(xx1), 'r', linewidth=2)
ix1 = np.linspace(mu1, mu1+std1)
iy1 = rv1.pdf(ix1)
verts1 = [(mu1, 0)] + list(zip(ix1, iy1)) + [(mu1+std1, 0)]
poly1 = Polygon(verts1, facecolor='0.7', edgecolor='0.5')
ax1.add_patch(poly1)
ax2 = fig.add_subplot(212)
plt.plot(xx2, rv2.pdf(xx2), 'r', linewidth=2)
ix2 = np.linspace(mu2, mu2+std2)
iy2 = rv2.pdf(ix2)
verts2 = [(mu2, 0)] + list(zip(ix2, iy2)) + [(mu2+std2, 0)]
poly2 = Polygon(verts2, facecolor='0.7', edgecolor='0.5')
ax2.add_patch(poly2)
plt.text(0.5, 0.1, "0.3413", horizontalalignment="center", fontsize=10)
plt.show()
정답 : $$ P(100 \le X \le 100) = p(0 \le Z \le 1) = 0.3413 $$
Q. 연습문제
그렇다면 IQ 가 120 이상인 학생의 비율은 얼마나 될까?
In [4]:
fig, ax = plt.subplots()
plt.plot(xx2, rv2.pdf(xx2), 'r', linewidth=2)
ix = np.linspace(mu2+2*std2, mu2+3*std2)
iy = rv2.pdf(ix)
verts = [(mu2+2*std2, 0)] + list(zip(ix, iy)) + [(mu2+3*std2, 0)]
poly = Polygon(verts, facecolor='0.7', edgecolor='0.5')
ax.add_patch(poly)
plt.text(2.5, 0.01, "0.0228", horizontalalignment="center", fontsize=10)
plt.show()
정답 : $$ \begin{align} P(X \ge 120) &= P(Z \ge 2) \\ &= 0.5 - P(0 \le Z \le 2) \\ &= 0.5 - 0.4772 = 0.0228 \\ \end{align} $$
{kind=link}
{kind=link}
{kind=link}
{kind=link}