표본을 분석하여 모집단의 특성을 규명하는 통계적 추론(statistical inference)의 방법으로는 가설검정과 앞 장에서 설명한 추정(estimation)이 있다.
추정은 표본으로부터 계산한 통계량을 사용하여 모수의 특성을 규명하는 것으로서, 이미 9장에서 다루었다. 가설검정은 모집단에 대해 어떤 가설을 설정하고 그 모집단으로부터 추출된 표본을 분석함으로써 가설의 타당성 여부를 결정하는 것이다.
예제) 다음 중 귀무가설로 바람직한 가설은 ?
$H_{0}$ : 전국 모의고사 평균이 80점이다 $\mu=80$
$H_{0}$ : 전국 모의고사 평균이 80점이 아니다 $\mu \ne 80$
tip)
실제로 검정할 수 없거나 검정하기에 곤란한 가설을 귀무가설로 설정하는 것은 바랍직하지 못하다
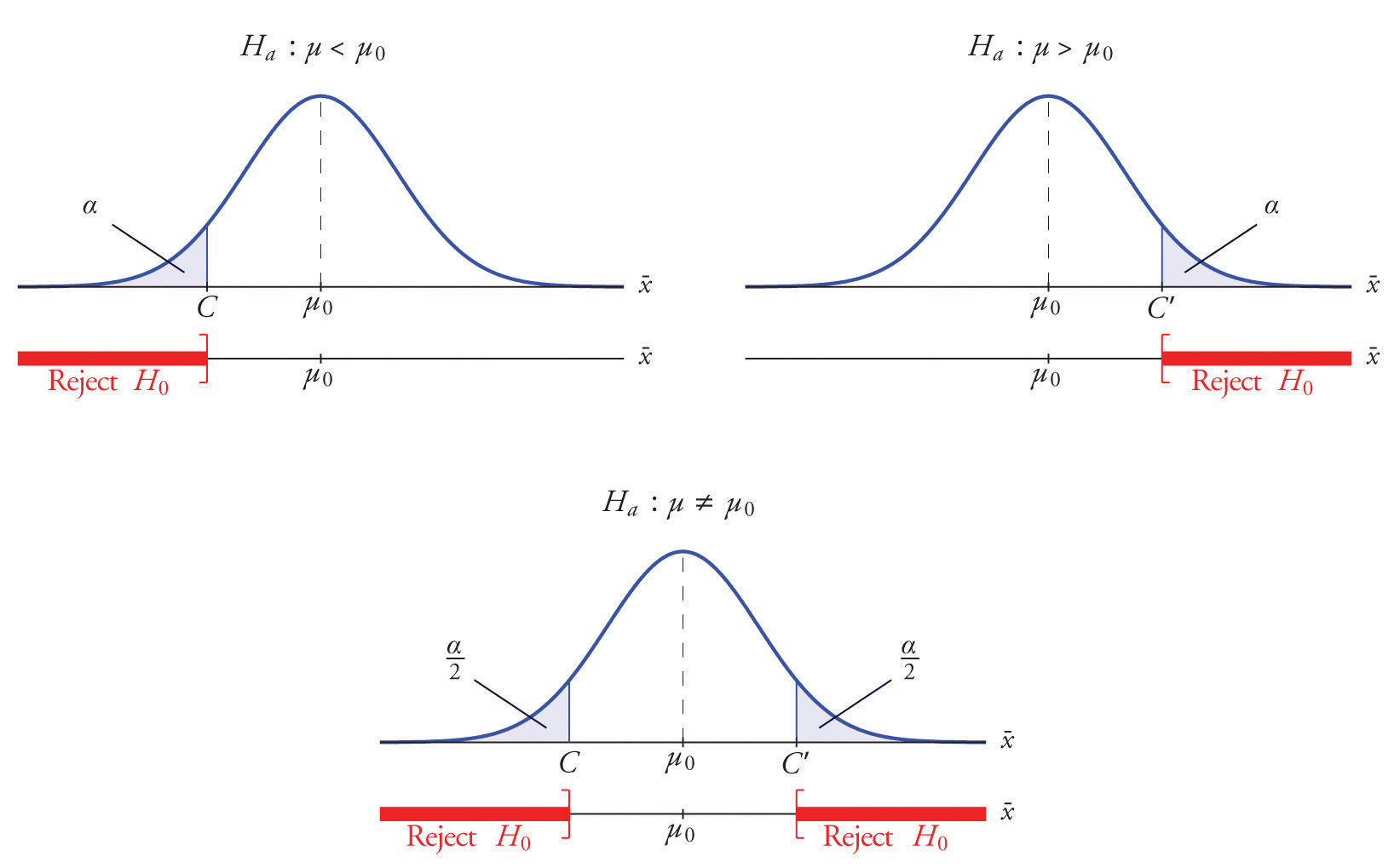
일반적으로 등식으로 표시된 가설을 귀무가설로 설정하는 것이 바람직하다
<img src="https://saylordotorg.github.io/text_introductory-statistics/section_12/72f0cd42fda04cdfb0341bcfe11601c1.jpg", width=800>
<img src="http://images.grasshopper.com/type1type2error.fw_.png", width=550> <img src="http://allpsych.com/wp-content/uploads/2014/08/type1and2error.gif", width=450>
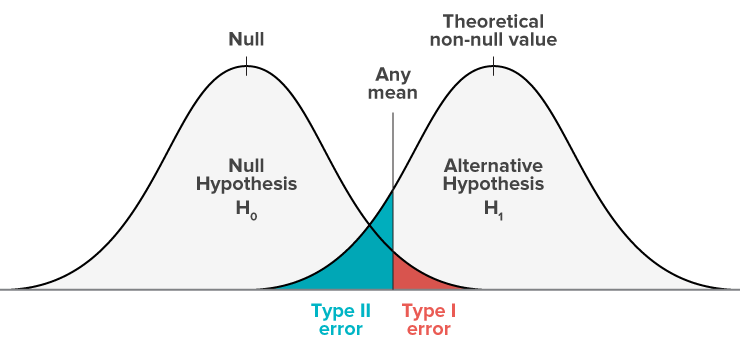
$\alpha-오류$ 와 $\beta-오류$ 의 관계
현실적으로
연구자의 관심대상이 되는 오류는 ?
따라서 가장 현실적이면서 좋은 통계적 검정법이란 ?
들어가기 앞서 - 귀무가설( null hypothesis )을 선언하는 방법
The test requires an unambiguous statement of a null hypothesis, which usually corresponds to a default "state of nature", for example "this person is healthy", "this accused is not guilty" or "this product is not broken".
( 검정에 있어서 귀무가설은 명백하여야 한다. 예를 들어 "이 사람은 건강하다", "이 사람은 무죄다", "이 제품은 정상이다.(부서지지 않았다)" 와 같이 자연적으로 0인 상태(default 상태) 로 선언해야 한다. )
예제 ( 1 )
$H_{0}$ : A라는 사람은 무죄다.
$H_{1}$ : A라는 사람은 유죄다.
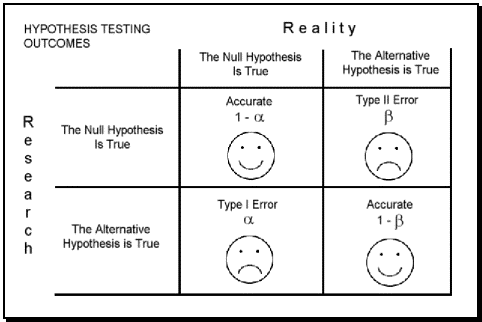
| 실제 $H_{0}$이 참인 경우 | 실제 $H_{0}$이 거짓인 경우 | |
|---|---|---|
| $H_{0}$ 기각 | $\alpha$ A가 무죄인데 유죄라 잘못 판단 ( high risk ) |
$1-\beta$ A가 유죄인데 유죄라고 옳게 판단 ( 연구성과있음 ) |
| $H_{0}$ 채택 | $1-\alpha$ A가 무죄인데 무죄라고 옳게 판단 ( 연구성과없음 ) |
$\beta$ A가 유죄인데 무죄라 판단 ( row risk ) |
예제 ( 2 )
$H_{0}$ : 이 비행기는 결함이 없다.
$H_{1}$ : 이 비행기는 결함이 있다.
| 실제 $H_{0}$이 참인 경우 | 실제 $H_{0}$이 거짓인 경우 | |
|---|---|---|
| $H_{0}$ 기각 | $\alpha$ 비행기에 결함이 없는데 있다고 잘못 판단 ( row risk ) |
$1-\beta$ 비행기에 결함이 있는데 있다고 옳게 판단 ( 연구성과있음 ) |
| $H_{0}$ 채택 | $1-\alpha$ 비행기에 결함이 없는데 없다고 옳게 판단 ( 연구성과없음 ) |
$\beta$ 비행기에 결함이 있는데 없다고 판단 ( high risk ) |
예제
국내 아이돌그룹 멤버들의 평균 키를 알기 위하여, 16명의 아이돌그룹 멤버의 키를 표본조사하였더니 평균 키가 175cm 였다. 국내 아이돌그룹 전체의 평균 키에 대한 표준편차가 5cm 라고 하면, 국내 아이돌그룹 멤버의 평균 키가 180cm 이상이라고 할 수 있을까? 유의수준 $(\alpha)$ 을 5%로 하여 검정하라.
In [1]:
import numpy as np
import scipy.stats as sp
import matplotlib.pylab as plt
from matplotlib.patches import Polygon
mu1 = 180; mu2 = 0; mu3 = 180; std1 = 5; std2 = 1; std3 = 1.25
rv1 = sp.norm(mu1, std1); rv2 = sp.norm(mu2, std2); rv3 = sp.norm(mu3, std3)
xx1 = np.linspace(mu1-4*std1, mu1+4*std1, 100)
xx2 = np.linspace(mu2-4*std2, mu2+4*std2, 100)
xx3 = np.linspace(mu3-16*std3, mu3+16*std3, 100)
# figure
fig = plt.figure(figsize=(7.5, 5))
# ax1
ax1 = fig.add_subplot(311)
plt.plot(xx1, rv1.pdf(xx1), 'r', linewidth=2)
plt.text(188, 0.06, r"Population($X$)", fontsize=18)
plt.text(188, 0.048, r"$\sigma = 5cm$", fontsize=15)
plt.yticks([])
# ax2
ax2 = fig.add_subplot(312)
plt.plot(xx2, rv2.pdf(xx2), 'r', linewidth=2)
ix2 = np.linspace(mu2-4*std2, mu2-1.62*std2)
iy2 = rv2.pdf(ix2)
verts2 = [(mu2-4*std2, 0)] + list(zip(ix2, iy2)) + [(mu2-1.62*std2, 0)]
poly2 = Polygon(verts2, facecolor='#1E90FF', edgecolor='0.5')
ax2.add_patch(poly2)
plt.text(2, 0.25, r"Z-dist($Z$)", fontsize=18)
plt.text(2, 0.20, r"$\sigma_{Z} = 1cm$", fontsize=15)
plt.yticks([])
# ax3
ax3 = fig.add_subplot(313)
plt.plot(xx3, rv3.pdf(xx3), 'r', linewidth=2)
ix3 = np.linspace(mu3-4*std3, mu3-1.62*std3)
iy3 = rv3.pdf(ix3)
verts3 = [(mu3-4*std3, 0)] + list(zip(ix3, iy3)) + [(mu3-1.62*std3, 0)]
poly3 = Polygon(verts3, facecolor='#1E90FF', edgecolor='0.5')
ax3.add_patch(poly3)
plt.text(190, 0.25, r"Sample($\bar{X}$)", fontsize=18)
plt.text(190, 0.20, r"$\sigma_{\bar{X}} = 1.25cm$", fontsize=15)
plt.yticks([])
plt.show()
{kind=link}
{kind=link}
{kind=link}