| Name | Roles | |
|---|---|---|
| Victor Starostenko | victor.starostenko@live.com | Feature Analysis, Logic Management, Coding, Project Management |
| Evie Phan | evphan@gmail.com | Feature Analysis, Frontend Design, Wireframes and Prototyping, Logo Design |
| Ashley DeSouza | ashley.souza@live.com | Feature Engineering, Data Cleaning and Transformation, Data Analysis |
| Shreyas | shreyas@ischool.berkeley.edu | Coding & Development, Data Mining, Frontend develpment |
Many companies have suffered extremely high costs associated with losing sensitive information due to security breaches, but what is even more troubling is that these companies kept their breaches under wraps. A few years ago this was the way things were done. Nobody wanted to be exposed for having weak security or fragile infrastructure, and so organizations endured the breach, paid for the consequences, and kept quiet about the details out of embarrassment. And then a few months later the same breach would happen to someone else.
By sharing as much information as possible about security breaches and what led to them, organizations will be able to more strategically and effectively fight the attackers. By uniting information, analysing it, and drawing conclusions it would be much easier to find commonalities in offending technologies or methods.
"Companies should share security breach information because that is the only way we will be able to cobble together a comprehensive picture of the threats and fight back."
Soteria is a project that focuses on exploring and analysing security breach data. For our analysis we will be using a VERIS Community Database. VERIS Community Database is a dataset of over 3,000 security incidents and breaches. It is also a set of metrics designed to provide a common language for describing security incidents in a structured and repeatable manner. By analysing and extracting interesting features we aim to gain understanding of which metrics and vectors of attack are user to target specific industries. We also plan to create a visualization/report viewing interface to be able to sift through the records and relevant data.**
VERIS Community Database VERIS is a Vocabulary for Event Recording and Incident Sharing. VERIS is a set of metrics designed to provide a common language for describing security incidents in a structured and repeatable manner. VERIS Community Database a dataset of over 3,000 security incidents and breaches.
VERIS Community Database GitHub repository
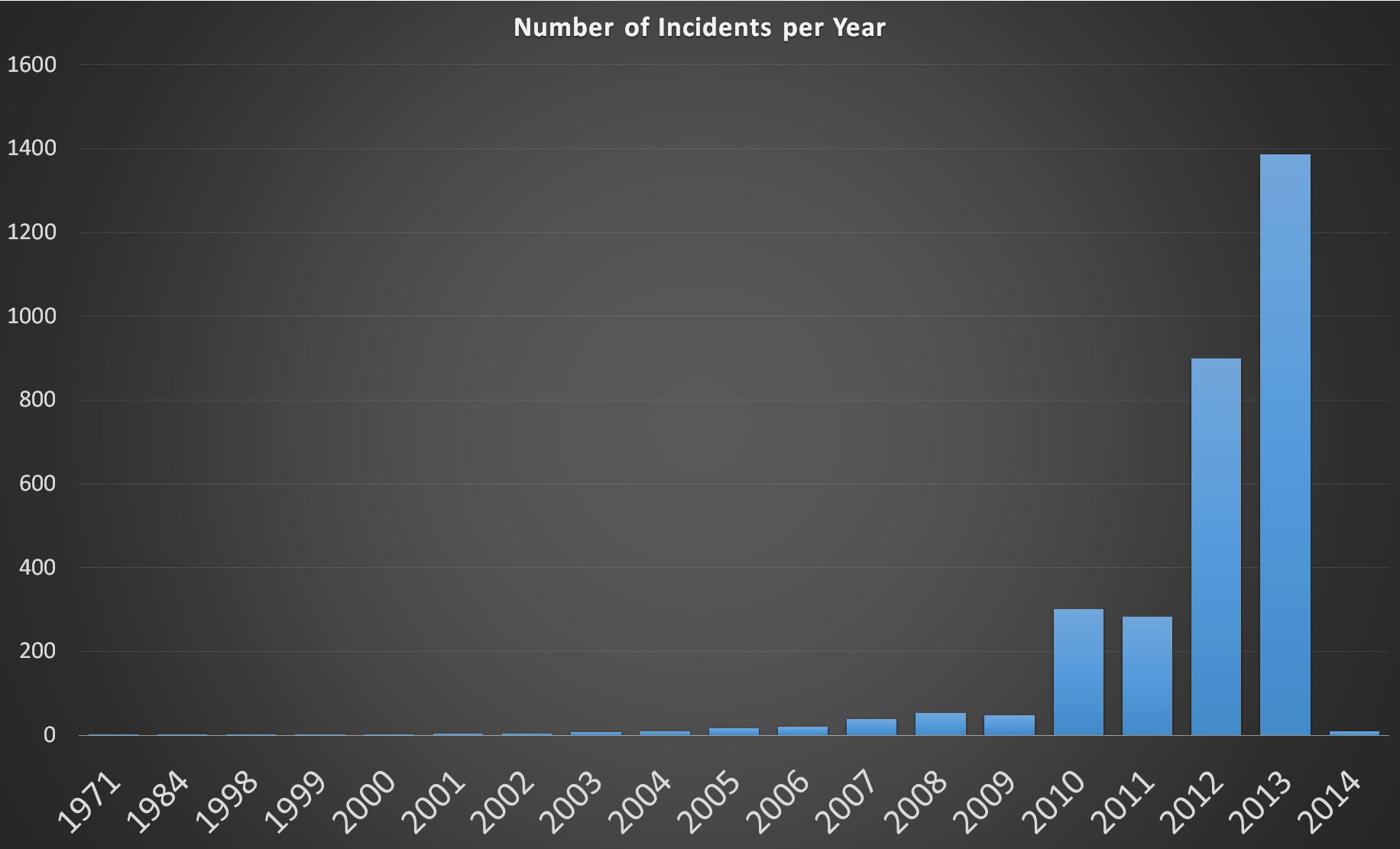
Looking at the data we are quickly able to extract interesting features. For eample, the bar graph below shows the number of breaches from 1971 to 2014:
Populating the interactive namespace from numpy and matplotlib
In [41]:
%pylab --no-import-all inline
%matplotlib inline
Importing relevant libraries
In [6]:
from __future__ import division
import pandas as pd
import numpy as np
import csv
Some attributes in the dataset are not needed for this analysis. Our starting point always remains unmodified, any changes to the dataset are recorded in new CSV and JSON documents. In this step we are removing some of the attributes that we found to be not relevant to our analysis.
The output is saved to a new document called: vcdb_preprocessed.csv
In [7]:
def main():
source = "../data/vcdb_categories_evie.csv"
result = "../data/vcdb_preprocessed.csv"
removed_fields = ["source_id","summary","related_incidents","notes","victim.locations_affected","victim.notes","victim.revenue.iso_currency_code","victim.secondary.amount","victim.secondary.victim_id","asset.management","asset.notes","attribute.confidentiality.notes","attribute.confidentiality.state","attribute.integrity.notes","attribute.availability.duration.unit","attribute.availability.duration.value","attribute.availability.notes","timeline.compromise.unit","timeline.compromise.value","timeline.containment.unit","timeline.containment.value","timeline.exfiltration.unit","timeline.exfiltration.value","targeted","impact.iso_currency_code","impact.notes","impact.overall_amount","impact.overall_min_amount","impact.overall_rating","plus.analysis_status","plus.analyst","plus.analyst_notes","plus.asset.total","plus.attribute.confidentiality.credit_monitoring","plus.attribute.confidentiality.credit_monitoring_years","plus.attribute.confidentiality.data_abuse","plus.attribute.confidentiality.data_misuse","plus.attribute.confidentiality.data_subject","plus.attribute.confidentiality.partner_number","plus.created","plus.dbir_year","plus.f500","plus.github","plus.issue_id","plus.master_id","plus.modified","plus.timeline.notification.day","plus.timeline.notification.month","plus.timeline.notification.year","data_total"]
removed_index = []
with open(source,"rb") as sourceh:
rdr= csv.reader(sourceh)
headers = rdr.next()
print len(headers)
with open(result, "wb") as new_csv_file:
wrtr = csv.writer(new_csv_file)
for i in range(len(headers)):
if headers[i] in removed_fields:
removed_index.append(i)
for i in removed_index[::-1]:
del headers[i]
wrtr.writerow(headers)
for row in rdr:
for index in removed_index[::-1]:
del row[index]
wrtr.writerow(row)
print len(headers)
print "No Errors"
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
As can be seen from the output above, we have removed a total of 50 attributes.
In this step, we are converting Industry Codes column to corresponding industry names.
We used the Census API to recode our data: http://www.census.gov/cgi-bin/sssd/naics/naicsrch?chart=2012
In [8]:
def main():
industry_index = 0
industry_code = {}
naics_file = "../data/2-digit_2012_Codes.csv"
preprocess_file = "../data/vcdb_preprocessed.csv"
preprocessed_file = "../data/vcdb_industry_processed.csv"
with open(naics_file, "rb") as csv_file:
reader = csv.reader(csv_file)
header = reader.next()
for row in reader:
industry_code[row[1]] = row[2]
with open(preprocess_file, "rb") as csv_file:
reader = csv.reader(csv_file)
header = reader.next()
for i in range(len(header)):
if header[i] == "victim.industry":
industry_index = i
break
with open(preprocessed_file, "wb") as new_csv_file:
writer = csv.writer(new_csv_file)
writer.writerow(header)
for row in reader:
if row[industry_index] in industry_code:
row[industry_index] = industry_code[row[industry_index]]
else:
row[industry_index] = None
writer.writerow(row)
print "No Errors"
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
To visualize what the code above did we compare the two dataframes. These are the first 5 rows from the original, coded column:
In [42]:
df_industry_coded = pd.read_csv("../data/vcdb_preprocessed.csv")
df_industry_recoded = pd.read_csv("../data/vcdb_industry_processed.csv")
df_industry_coded[['victim.industry']].head()
Out[42]:
And these are the same 5 rows from the recoded dataset:
In [40]:
df_industry_recoded[['victim.industry']].head()
Out[40]:
One of the challenges with the data was the way breach discovery timeline was represented. This timeline was represented by two attributes: timeline.discovery.unit and timeline.discovery.value.
These attributes were not normalized and spread out across multiple values, which represented seconds, minutes, hours, days, weeks, months, and years. Taking the median of these values (days), we recoded each value in terms of days. The new column describes how many days it took for the breach to be discovered.
The new attribute is called: timeline.discovery.day_count.
In [86]:
def main():
unit = ""
value = 0
with open("../data/vcdb_industry_processed.csv", "rb") as csv_file:
rdr = csv.reader(csv_file)
header = rdr.next()
with open("../data/vcdb_date_processed.csv", "wb") as new_csv_file:
wrtr = csv.writer(new_csv_file)
for i in range(len(header)):
if header[i] == "timeline.discovery.unit":
unit = i
elif header[i] == "timeline.discovery.value":
value = i
else:
pass
header[value] = "timeline.discovery.day_count"
del header[unit]
wrtr.writerow(header)
for row in rdr:
if row[value] == "":
if row[unit] == "Seconds":
row[value] = 0.0007
elif row[unit] == "Minutes":
row[value] = 0.021
elif row[unit] == "Hours":
row[value] = 0.5
elif row[unit] == "Weeks":
row[value] = 14
elif row[unit] == "Days":
row[value] = 15
elif row[unit] == "Months":
row[value] = 182
elif row[unit] == "Years":
row[value] = 365
elif row[unit] == "Unknown":
row[value] = None
else:
if row[unit] == "Seconds":
row[value] = int(row[value])/(24.0*60.0*60.0)
elif row[unit] == "Minutes":
row[value] = int(row[value])/(24.0*60.0)
elif row[unit] == "Hours":
row[value] = int(row[value])/24.0
elif row[unit] == "Weeks":
row[value] = int(row[value])*7
elif row[unit] == "Days":
row[value] = int(row[value])
elif row[unit] == "Months":
row[value] = int(row[value])*30
elif row[unit] == "Years":
row[value] = int(row[value])*365
del row[unit]
wrtr.writerow(row)
print "No Errors"
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
This is the original set of columns:
In [47]:
df_timeline_discovery = pd.read_csv("../data/vcdb_industry_processed.csv")
df_timeline_discovery[['timeline.discovery.unit', 'timeline.discovery.value']].head(10)
Out[47]:
And this is the recoded column:
In [50]:
df_timeline_discovery = pd.read_csv("../data/vcdb_date_processed.csv")
df_timeline_discovery[['timeline.discovery.day_count']].head(10)
Out[50]:
In [84]:
def main():
source = "../data/vcdb_date_processed.csv"
result = "../data/vcdb_columns_removed_processed.csv"
remove_fields = ["asset.accessibility","asset.cloud","asset.hosting","asset.ownership",
"asset.assets.Kiosk.Term", "asset.assets.Media"]
remove_index = []
with open(source,"rb") as csv_file:
rdr= csv.reader(csv_file)
headers = rdr.next()
with open(result, "wb") as new_csv_file:
wrtr = csv.writer(new_csv_file)
for i in range(len(headers)):
if headers[i] in remove_fields:
remove_index.append(i)
for i in remove_index[::-1]:
del headers[i]
wrtr.writerow(headers)
for row in rdr:
for index in remove_index[::-1]:
del row[index]
wrtr.writerow(row)
print "No Errors"
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
In [85]:
def main():
preprocess_file = "../data/vcdb_columns_removed_processed.csv"
preprocessed_file = "../data/vcdb_empcount_processed.csv"
with open(preprocess_file, "rb") as csv_file:
reader = csv.reader(csv_file)
header = reader.next()
for i in range(len(header)):
if header[i] == "victim.employee_count":
employee_count = i
with open(preprocessed_file, "wb") as new_csv_file:
writer = csv.writer(new_csv_file)
writer.writerow(header)
for row in reader:
if row[employee_count] == "Unknown":
row[employee_count] = "NaN"
#print "Unknown found"
elif row[employee_count].split()[0] == "Over":
#print "found"
row[employee_count] = float(row[employee_count].split()[1])+float(row[employee_count].split()[1])/2
elif len(row[employee_count].split()) == 3 and row[employee_count].split()[1] == "to":
row[employee_count] = (float(row[employee_count].split()[0]+row[employee_count].split()[2])/2)
writer.writerow(row)
print "No Errors"
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
# victor
In [86]:
def main():
source = "../data/vcdb_empcount_processed.csv"
result = "../data/vcdb_fully_processed.csv"
df_elipses = pd.read_csv("../data/vcdb_empcount_processed.csv")
new_headers = []
with open(source,"rb") as csv_file:
rdr= csv.reader(csv_file)
headers = rdr.next()
for header in headers:
if '...' in header:
header = header.replace("...","_")
new_headers.append(header)
df_elipses.columns = new_headers
df_elipses.to_csv("../data/vcdb_fully_processed.csv")
print "No Errors"
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
In [82]:
df = pd.read_csv("../data/vcdb_fully_processed.csv")
df.to_csv("../data/vcdb_fully_processed.csv", na_rep='NaN',index=False)
In [83]:
df_json = pd.read_csv("../data/vcdb_fully_processed.csv")
df_json.to_json("../data/vcdb_fully_processed.json", orient='records')
When we looked at breaches on their own with respect to the features provided, the features looked sparse, they were booleans and we felt like on their own, they were not enough to deduct a conclusion from.
So, we decided to look at pairwise combination of breaches on those same features and figure out how similar they were. These are key attributes that a security professional would like to look at, as given these parameters of the breach, were there other breaches that were similar to it, and hence such an analysis would add more context to the breach being scrutinized at the moment.
As we had 3,084 records, doing a pairwise combination of those breaches would result in 4,753,986 possible combinations, we had to develop our script for distributed computing.
Hence we developed a map-reduce script using python MRJob library, to calculate the similarity of breaches
The script below is produced for evaluation purposes. To run the script please run it from the command line using the following commands
#! /usr/bin/env python
from __future__ import division
from mrjob.job import MRJob
from itertools import combinations
# from sklearn.metrics import jaccard_similarity_score
import numpy as np
import sys
class AttackSimilarity(MRJob):
# INPUT_PROTOCOL = JSONValueProtocol
def extract_incident(self, _, line):
record = line.split(',')
# print record
if record[0] != 'incident_id':
feature = record[1:]
incident = record[0]
yield incident, list(feature)
def combine_incident(self, incident, feature):
allfeatures = list(feature)
yield incident, list(allfeatures[0])
def distribute_incident(self, incd, incdfeat):
yield "all" , [incd, list(incdfeat)]
def similar_incident(self, _, allincidents):
for (inc_a, feat_a), (inc_b, feat_b) in combinations(list(allincidents), r=2):
feat_a_array = np.array(feat_a, dtype='int')
feat_b_array = np.array(feat_b, dtype='int')
# similarity = jaccard_similarity_score(feat_a_array, feat_b_array)
feat_a_mag = np.sqrt(np.dot(feat_a_array, feat_a_array))
feat_b_mag = np.sqrt(np.dot(feat_b_array, feat_a_array))
similarity = float(np.dot(feat_a_array, feat_b_array))/ (feat_a_mag * feat_b_mag)
sys.stderr.write("Similarity: ({0},{1})\n".format([inc_a, inc_b],similarity))
if similarity > 0.90 :
yield [inc_a, inc_b], similarity
def steps(self):
"""
MapReduce Steps:
extract_incident : <_, line> => <incident, feature>
combine_incident : <incident, [feature]> => <incident, allfeatures>
map_incident : <incident, [incedentfeatures] => <"all", [[incident, features]]
reduce_incident : <_, allincidents> => <[incident_pairs], similarity>
"""
return [
self.mr(mapper=self.extract_incident, reducer=self.combine_incident),
self.mr(mapper=self.distribute_incident, reducer=self.similar_incident)
]
if __name__ == '__main__':
AttackSimilarity.run()
Command
$ head -n 10 data/vcdb_mrjob2.csv | python attack_similiarity.py
Output
no configs found; falling back on auto-configuration
no configs found; falling back on auto-configuration
creating tmp directory /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534
reading from STDIN
writing to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-0-mapper_part-00000
Counters from step 1:
(no counters found)
writing to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-0-mapper-sorted
> sort /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-0-mapper_part-00000
writing to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-0-reducer_part-00000
Counters from step 1:
(no counters found)
writing to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-1-mapper_part-00000
Counters from step 2:
(no counters found)
writing to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-1-mapper-sorted
> sort /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-1-mapper_part-00000
writing to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-1-reducer_part-00000
attack_similiarity.py:47: RuntimeWarning: invalid value encountered in double_scalars
similarity = float(np.dot(feat_a_array, feat_b_array))/ (feat_a_mag * feat_b_mag)
Counters from step 2:
(no counters found)
Moving /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/step-1-reducer_part-00000 -> /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/output/part-00000
Streaming final output from /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534/output
["002599D4-A872-433B-9980-BD9F257B283F", "0096EF99-D9CB-4869-9F3D-F4E0D84F419B"] 0.94868329805051377
["002599D4-A872-433B-9980-BD9F257B283F", "00EB741C-0DFD-453E-9AC2-B00E512897DA"] 0.94868329805051377
["0096EF99-D9CB-4869-9F3D-F4E0D84F419B", "00EB741C-0DFD-453E-9AC2-B00E512897DA"] 0.99999999999999978
["00DCB3AD-AF4C-4AC1-8A6E-682DB697C727", "00EB741C-0DFD-453E-9AC2-B00E512897DA"] 0.94280904158206325
removing tmp directory /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185609.078534
runners:
emr:
aws_access_key_id: <AMAZON KEY>
aws_secret_access_key: <AMAZON SECRET KEY>
ec2_core_instance_type: m1.large
ec2_key_pair: <KEY-PAIR NAME>
ec2_key_pair_file: <ABSOLUTE PATH TO KEY-FILE : permissions.pem >
num_ec2_core_instances: 5
pool_wait_minutes: 2
pool_emr_job_flows: true
ssh_tunnel_is_open: true
ssh_tunnel_to_job_tracker: trueCommand
$ head -n 10 data/vcdb_mrjob2.csv | python attack_similiarity.py -c mrjob.conf -r emr
Output
using existing scratch bucket mrjob-51b9493c1a467671
using s3://mrjob-51b9493c1a467671/tmp/ as our scratch dir on S3
creating tmp directory /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185623.814405
writing master bootstrap script to /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185623.814405/b.py
reading from STDIN
Copying non-input files into s3://mrjob-51b9493c1a467671/tmp/attack_similiarity.shreyas.20140506.185623.814405/files/
Attempting to find an available job flow...
When AMI version is set to 'latest', job flow pooling can result in the job being added to a pool using an older AMI version
Adding our job to existing job flow j-19L00U5JOP27C
Job launched 30.4s ago, status RUNNING: Running step (attack_similiarity.shreyas.20140506.185623.814405: Step 1 of 2)
Opening ssh tunnel to Hadoop job tracker
Connect to job tracker at: http://1.0.0.127.in-addr.arpa:40760/jobtracker.jsp
Job launched 62.1s ago, status RUNNING: Running step (attack_similiarity.shreyas.20140506.185623.814405: Step 1 of 2)
Unable to load progress from job tracker
Job launched 92.6s ago, status RUNNING: Running step (attack_similiarity.shreyas.20140506.185623.814405: Step 1 of 2)
Job launched 123.0s ago, status RUNNING: Running step (attack_similiarity.shreyas.20140506.185623.814405: Step 1 of 2)
Job launched 153.4s ago, status RUNNING: Running step (attack_similiarity.shreyas.20140506.185623.814405: Step 2 of 2)
Job launched 183.9s ago, status RUNNING: Running step (attack_similiarity.shreyas.20140506.185623.814405: Step 2 of 2)
Job completed.
Running time was 189.0s (not counting time spent waiting for the EC2 instances)
Fetching counters from SSH...
Counters from step 1:
File Input Format Counters :
Bytes Read: 187909
File Output Format Counters :
Bytes Written: 13995
FileSystemCounters:
FILE_BYTES_READ: 1531
FILE_BYTES_WRITTEN: 1050825
HDFS_BYTES_READ: 4380
HDFS_BYTES_WRITTEN: 13995
S3_BYTES_READ: 187909
Job Counters :
Launched map tasks: 30
Launched reduce tasks: 8
Rack-local map tasks: 30
SLOTS_MILLIS_MAPS: 264350
SLOTS_MILLIS_REDUCES: 162928
Total time spent by all maps waiting after reserving slots (ms): 0
Total time spent by all reduces waiting after reserving slots (ms): 0
Map-Reduce Framework:
CPU time spent (ms): 64670
Combine input records: 0
Combine output records: 0
Map input bytes: 15814
Map input records: 10
Map output bytes: 14013
Map output materialized bytes: 5293
Map output records: 9
Physical memory (bytes) snapshot: 13905297408
Reduce input groups: 9
Reduce input records: 9
Reduce output records: 9
Reduce shuffle bytes: 5293
SPLIT_RAW_BYTES: 4380
Spilled Records: 18
Total committed heap usage (bytes): 14167834624
Virtual memory (bytes) snapshot: 50262282240
Counters from step 2:
File Input Format Counters :
Bytes Read: 46251
File Output Format Counters :
Bytes Written: 404
FileSystemCounters:
FILE_BYTES_READ: 1397
FILE_BYTES_WRITTEN: 1188752
HDFS_BYTES_READ: 51921
S3_BYTES_WRITTEN: 404
Job Counters :
Data-local map tasks: 31
Launched map tasks: 35
Launched reduce tasks: 8
Rack-local map tasks: 2
SLOTS_MILLIS_MAPS: 273029
SLOTS_MILLIS_REDUCES: 145161
Total time spent by all maps waiting after reserving slots (ms): 0
Total time spent by all reduces waiting after reserving slots (ms): 0
Map-Reduce Framework:
CPU time spent (ms): 30780
Combine input records: 0
Combine output records: 0
Map input bytes: 13995
Map input records: 9
Map output bytes: 14094
Map output materialized bytes: 5978
Map output records: 9
Physical memory (bytes) snapshot: 16541917184
Reduce input groups: 1
Reduce input records: 9
Reduce output records: 4
Reduce shuffle bytes: 5978
SPLIT_RAW_BYTES: 5670
Spilled Records: 18
Total committed heap usage (bytes): 16876306432
Virtual memory (bytes) snapshot: 57137254400
Streaming final output from s3://mrjob-51b9493c1a467671/tmp/attack_similiarity.shreyas.20140506.185623.814405/output/
["00EB741C-0DFD-453E-9AC2-B00E512897DA", "002599D4-A872-433B-9980-BD9F257B283F"] 0.94868329805051377
["00EB741C-0DFD-453E-9AC2-B00E512897DA", "0096EF99-D9CB-4869-9F3D-F4E0D84F419B"] 0.99999999999999978
["002599D4-A872-433B-9980-BD9F257B283F", "0096EF99-D9CB-4869-9F3D-F4E0D84F419B"] 0.94868329805051377
["00DCB3AD-AF4C-4AC1-8A6E-682DB697C727", "0096EF99-D9CB-4869-9F3D-F4E0D84F419B"] 0.94280904158206325
removing tmp directory /var/folders/5p/jqdjg7z572d5d40t2pfc2nh80000gn/T/attack_similiarity.shreyas.20140506.185623.814405
Removing all files in s3://mrjob-51b9493c1a467671/tmp/attack_similiarity.shreyas.20140506.185623.814405/
For the entire dataset, following is the time statistics
real 36m51.968s
user 0m2.935s
sys 0m0.753smeasures of similarity changed the output.
Jaccard Similarity earlier, which gave us 24,442 for similarity condition of exact match 1.0Cosine Similarity gave us 102670 records for similarity condition of > 0.9Although the feature matrices were sparse, we got a lot of high similarity values.
But to dig deeper into these intuitions, we did a comparison analysis.
In this step we generate a side-by-side comparison of various attributes that we believe are determinating factors of the after-effects of a breach. This is done for each victim combination that is returned from the Map-Reduce step. The results are stored in a csv file (Location: ../data/vcdb_similarity_compariosn.csv)
In [2]:
from __future__ import division
import pandas as pd
import numpy as np
import csv
import re
def main():
markdown_file = "../similar_attacks.md"
preprocessed_file = "../data/vcdb_fully_processed.csv"
output_file = "../data/vcdb_similarity_comparison.csv"
relevant_attributes = ["incident_id", "industry.categories", "victim.victim_id", "timeline.incident.month", "timeline.incident.year", "timeline.discovery.day_count", "attribute.confidentiality.data_total", "actor.internal", "actor.external"]
incident_id = {}
industry_ids = []
relevant_attributes_index = []
row_attributes = []
new_header = []
new_row = []
victim_num = 1
regex = r'\w{8}\-\w{4}\-\w{4}\-\w{4}\-\w{12}'
with open(markdown_file, "rb") as md_file:
for i in md_file:
searchObj = re.findall(regex, i, flags = 0)
if searchObj:
industry_ids.append((searchObj[0], searchObj[1]))
else:
pass
with open(output_file, "wb") as new_csv_file:
wrtr = csv.writer(new_csv_file)
with open(preprocessed_file, "rb") as csv_file:
reader = csv.reader(csv_file)
headers = reader.next()
for i in range(len(headers)):
if headers[i] in relevant_attributes:
relevant_attributes_index.append(i)
else:
pass
for i in range(len(relevant_attributes_index)):
new_header.append("victim"+ str(victim_num) + "_" + headers[relevant_attributes_index[i]])
victim_num += 1
new_header.append("victim"+ str(victim_num) + "_" + headers[relevant_attributes_index[i]])
victim_num -= 1
wrtr.writerow(new_header)
for row in reader:
row_attributes= []
for i in range(1,len(relevant_attributes_index)):
row_attributes.append(row[relevant_attributes_index[i]])
incident_id[row[relevant_attributes_index[0]]] = row_attributes
for key in range(len(industry_ids)):
new_row = []
if industry_ids[key][0] in incident_id.keys() and industry_ids[key][1] in incident_id.keys():
new_row.append(industry_ids[key][0])
for vic_one in incident_id[industry_ids[key][0]]:
new_row.append(vic_one)
idx_vic_2 = 1
new_row.insert(idx_vic_2, industry_ids[key][1])
for vic_two in incident_id[industry_ids[key][1]]:
idx_vic_2 += 2
new_row.insert(idx_vic_2, vic_two)
wrtr.writerow(new_row)
else:
pass
if __name__ == "__main__":
try:
main()
except Exception as e:
print 'Something went wrong ', e
In this step we perform further analysis on the victims of security breaches. Here we generate another csv file that provides statistical information about each security breach such as the number of times that particular breach occured.
The input file is the output file that is generated from the previous step, i.e. the file at location "../data/vcdb_similarity_comparison.csv"
The resulting output file is stored at location "../data/vcdb_similarity_comparison_2.csv"
In [ ]:
from pandas import read_csv
from urllib import urlopen
import csv
page = urlopen("../data/vcdb_similarity_comparison.csv")
df = read_csv(page)
grouped_object = df.groupby("victim1_incident_id")
grouped_object["victim1_victim.victim_id"].describe().to_csv("../data/vcdb_similarity_comparison_2.csv")
{kind=link}
{kind=link}