Please read the assignment overview page carefully before proceeding. This page contains information about formatting (including formats etc), group sizes, and many other aspects of handing in the assignment.
If you fail to follow these simple instructions, it will negatively impact your grade!
Due date and time: The assignment is due on Sunday Februrary 28th, 2016 at 23:55. Hand in your IPython notebook file (with extension .ipynb) via http://peergrade.io.
Peergrading date and time: Remember that after handing in you have 24 hours to evaluate a few assignments written by other members of the class. Thus, the peer evaluations are due on Monday February 29th, 2016 at 23:55.
Start by downloading these four datasets: Data 1, Data 2, Data 3, and Data 4. The format is .tsv, which stands for tab separated values.
Each file has two columns (separated using the tab character). The first column is $x$-values, and the second column is $y$-values.
It's ok to just download these files to disk by right-clicking on each one, but if you use Python and urllib or urllib2 to get them, I'll really be impressed. If you don't know how to do that, I recommend opening up Google and typing "download file using Python" or something like that. When interpreting the search results remember that stackoverflow is your friend.
numpy function mean, calculate the mean of both $x$-values and $y$-values for each dataset. numpy to calculate the Pearson correlation between $x$- and $y$-values for all four data sets (also to three decimal places).scipy's linregress. It works like this
from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(x,y)matplotlib.pyplot. Use a two-by-two subplot to put all of the plots nicely in a grid and use the same $x$ and $y$ range for all four plots. And include the linear fit in all four plots. (To get a sense of what I think the plot should look like, you can take a look at my version here.)We investigate the types of crime and how they take place across San Francisco's police districts.
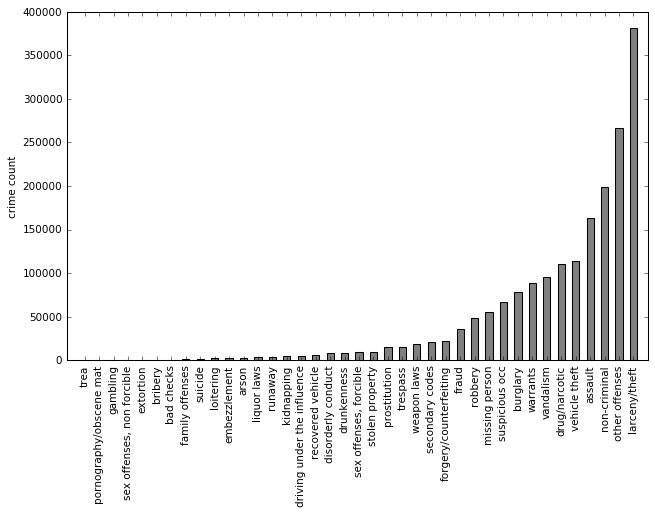
P(crime).P(crime|district).P(crime|district)/P(crime). That ratio is equal to 1 if the crime occurs at the same level within a district as in the city as a whole. If it's greater than one, it means that the crime occurs more frequently within that district. If it's smaller than one, it means that the crime is rarer within the district in question than in the city as a whole.The goal of this exercise is to create a useful real-world version of the example on pp153 in DSFS. We know from last week's exercises that the focus crimes PROSTITUTION, DRUG/NARCOTIC and DRIVING UNDER THE INFLUENCE tend to be concentrated in certain neighborhoods, so we focus on those crime types since they will make the most sense a KNN - map.
geoplotlib to plot all incidents of the three crime types on their own map using geoplotlib.kde(). This will give you an idea of how the varioius crimes are distributed across the city.scikit-learn's KNeighborsClassifier. If you end up using the latter (recommended), you may want to check out this example to get a sense of the usage.geoplotlib.dot(). K. Investigate Chief Suneman's idea is that the Red Baron might pick the time of his attacks according to a pattern that we can detect using the powers of data science.
If he's right, we can identify the time of the next attack, which will help us end this insanity once and for all. Well, let's see if he is right!
Red Baron in the resolution field and use the day of the week to predict the hour of the day when he is attacking, e.g. use linear regression to infer the hour of the day based on the weekday! Again, take 4/5 of the data for training and then calculate goodness of fit using $R^2$ on the rest 1/5. Don't forget to rescale your input variables! (Note 1: My goodness of fit after using the weekdays is only around 0.618). (Note 2: For multivariate regression, as always you can simply re-use the code in the DSFS book (Chapters 14-15) or scikit-learn).
In [ ]:
{kind=link}
{kind=link}