A program is a sequence of instructions that specifies how to perform a computation. The computation might be something mathematical, such as solving a system of equations or finding the roots of a polynomial, but it can also be a symbolic computation, such as searching and replacing text in a document or something graphical, like processing an image or playing a video. (Downey, 2015)
Much of this notebook, where indicated and elsewhere, is copied from the following book:
Allen Downey, Think Python: How to think like a computer scientist, 2nd edition, Green Tea Press, 2015.
Quotes from the book, which may be freely downloaded here, are used under the terms of the Creative Commons Attribution-NonCommercial 3.0 Unported License, which is available at http://creativecommons.org/licenses/by-nc/3.0/.
Natural languages are the languages people speak, such as English, Spanish, and French. They were not designed by people (although people try to impose some order on them); they evolved naturally.
Formal languages are languages that are designed by people for specific applications. For example, the notation that mathematicians use is a formal language that is particularly good at denoting relationships among numbers and symbols. Chemists use a formal language to represent the chemical structure of molecules. And most importantly:
Programming languages are formal languages that have been designed to express computations.
The set of formal statements that constitute a program are known as code. The programmer writes code into files that are saved using a file extension that indicates the language the code is written in; examples include:
Note that they are textual, i.e., human-readable format (as opposed to machine code: a binary representation of the code).
See the file fddhs.py for an example
The formal programming languages have associated syntax rules that come in two flavors: one pertaining to tokens and another to structure [how tokens may be combined]. Tokens are the basic elements of the language, such as words, numbers, and chemical elements. Programming languges differ greatly in both the specific form of the tokens used and the structures they may form.
One of the most common error messages a programmer encounters when beginning to use a new language is the infamous: Syntax Error! For learners of natural languages, structural errors much more common are ;)
In [ ]:
# example of a syntax error
Computer: please write my thesis.
In [ ]:
# example of an error in structure
'a' + 1
The meaning of a computer program is unambiguous and literal, and can be understood entirely by analysis of the tokens and structure.
Formal languages are more dense than natural languages, so it takes longer to read them. Also, the structure is important, so it is not always best to read from top to bottom, left to right. Instead, learn to parse the program in your head, identifying the tokens and interpreting the structure. Finally, the details matter. Small errors in spelling and punctuation, which you can get away with in natural languages, can make a big difference in a formal language. (Downey, 2015)
Partly because programming languages have rather terse syntax (some are worse than others!), it is considered a good custom to annotate the computational “business”-portions of programs with comments. Comments are portions of the code that are not parsed by either the interpreter or the compiler, i.e., these are “left out” from the translation to machine instructions. Comments are thus exempt of syntax-checking and meaning-parsing applied to all other code.
Here is an example of a comment in the Python language. Whenever the hash-sign (‘#’) is encountered, parsing of the current line is stopped and the parser (interpreter or compiler) moves to the next line.
In [ ]:
2 # this is the number two
This is the ‘traditional’ way of thinking about programming: a two-stage process of execution
The ‘compilation’ stage allows, amongst other things, the compiler to optimize the execution of the CPU-level instructions with respect to more-or-less detailed knowledge of the processor and memory layout of the computer performing the computations. Note also that once a program has been compiled to be executable, it is no longer human-readable.
Examples of (important) compiled languages include:
These are executed line-by-line, in a read-evaluate-print-loop (REPL).
bash (and other shells)python interpreterWhen working in a field with computational elements, you are likely to come across the term script. Just like in a movie or a play, the script is an explicit description of what operations are going to be run, and in which order. Another analogy is that of a cooking recipe.
Yes, you could call them that. It is in fact possible to execute a notebook, which in effect means excuting each cell of the notebook from top to bottom.
Data science pipelines are often specified as scripts and then executed. Because the script will run in exactly the same fashion every time it is run, the pipeline is thus rendered reproducible. This is necessary precondition for any findings your may report being reproducible. If in addition to writing your analyses as scripts, you also share them with your peers, well, then your work also becomes open.
Following Chapter 2 in (Downey, 2015).
One of the most powerful features of a programming language is the ability to manipulate variables. A variable is a name that refers to a value." (Downey, 2015)
Variables are assigned values; in most programming languages, the assignment operator is the equal-sign (=). Assignment statements are read from left-to-right, here are a couple of python-assignments:
In [ ]:
message = "Is it time for a break yet?"
n = 42
electron_mass_MeV = 0.511
The programmer is free to choose the names of the variables she wishes to use in the code, as long as they do not violate the language’s syntactic rules. Common to most languages is that the following variable names are syntactically incorrect.
Never begin the name of a variable with a digit, or pretty much any other non-letter character (there are a few exceptions, such as underscore, _):
In [ ]:
2fast = 140
In [ ]:
@home = False
In [ ]:
no spaces = 'a space'
In Python, to see what a variable contains (maybe we forgot!), we can simply write the name of the variable on a line and execute it, or use the built-in print-command
In [ ]:
n
In [ ]:
print(message)
Note that a variable name is like a pointer to whatever data the assignment operation dictates. In interpreted languages, one does not need to pre-define what the variable is to contain: the interpreter figures this out on-the-fly. Similarly, the assignment to a variable can happen multiple times in the ‘lifetime’ of a program: each assignment simply moves the pointer to a new data object.
The following lines of code calculate and print the first few values of the Fibonacci sequence; make sure you understand what values are being assigned to the variables a, b and c.
In [ ]:
a = 0
b = 1
c = a + b
print(c)
a = b
b = c
c = a + b
print(c)
a = b
b = c
c = a + b
print(c)
a = b
b = c
c = a + b
print(c)
a = b
b = c
c = a + b
print(c)
a = b
b = c
c = a + b
print(c)
Avoid using the lowercase letter ‘l’, uppercase ‘O’, and uppercase ‘I’. Why? Because the l and the I look a lot like each other and the number 1. And O looks a lot like 0.
Each programming language ‘reserves’ some portion of typically the English (natural) language as keywords that are associated with specific (typically low-level) computational operations.
Practically all languages use the keywords if, else and for for ‘control flow’ of program execution. In Python, not, True, False and None are used to define logic:
In [ ]:
two_greater_than_one = (2 > 1)
print(two_greater_than_one)
if two_greater_than_one:
print('Correct')
NB Keywords cannot be used as variable names! Try, and you will get a Syntax Error.
In [ ]:
In [ ]:
n = 42
m = n + 25
print(m)
A statement is a unit of code that has an effect, like creating a variable or displaying a value (there are three statements in the code block above). When you type a statement, the interpreter executes it, which means that it does whatever the statement says.
Operators are one of the ways we can manipulate the data referenced by our variables. The usual mathematical operators are omnipresent, but things get interesting when we start applying operations to non-numeric objects. In Python, we could e.g. multiply a string by an integer, or in Matlab divide a 2D matrix of numbers by a 1D vector to obtain the least-squares estimate of the solution to a set of linear equations! But we digress...
In [ ]:
pow(2, 63) - 1
which is called: "nine quintillion two hundred twenty-three quadrillion three hundred seventy-two trillion thirty-six billion eight hundred fifty-four million seven hundred seventy-five thousand eight hundred seven" (in case you were wondering).
In practice, computers can perform arithmetic on arbitrarily large integers, as long as the language implemeting the computing suitably keeps track of what's going on in memory
a.k.a real numbers, or just "floats". What is the powers-of-two representation of the real number 0.1? What about the value of $\pi$ (an irrational number)? There are none! If you're interested precisely how floating point numbers are represented in binary form, check out this wiki page on the topic, but bewarned: it's hairy!
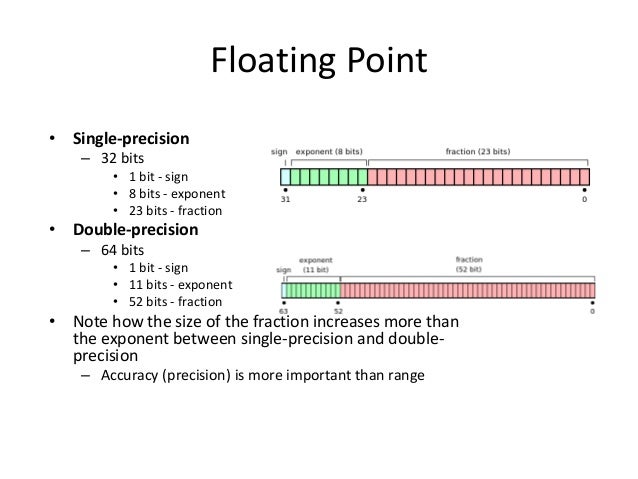
The most relevant parameter for floats is not its size, but its precision.
You can think of floating point precision as the number of digits after the decimal comma. For example:
$\frac{2}{3} \sim 0.6667$ is a more precise representation than $\frac{2}{3} \sim 0.7$
Like integers, real number need to be stored using some number of bits (and a scheme for representing it, as discussed above). You are likely to come across the terms ‘float’ and ‘single’: these refer to real numbers represented using 32-bit resolution. A ‘double’ refers to a 64-bit representation of a number. It is beyond the scope of this course to go into the details of under which conditions one representation/precision is more appropriate than the other. Suffice it to say: it’s better to err on the side of caution and use doubles. This is indeed what all mainstream interpreted languages do.
We'll return to the issue of floats vs. doubles below in the context of the limits of memory (not yours, the computer's).
In [ ]:
a_character = '*' # a single character
one_string = 'I am a ' # several characters in a row = a string
another_string = "Snowflake" # single or double quotes work in Python
print(one_string + another_string)
print(3 * another_string + a_character)
There is all manner of mayhem associated with character strings in programming languages. The thorniest issue is related to encoding: just like floats need to be represented as a sequence of bits, so do characters.
The most simple character encoding scheme is ASCII: an 8-bit translation table between a number between one and 255 ($=2^8-1$), and the corresponding character.
In [ ]:
print("The binary representation of the letter 'G' is:", bin(ord('G'))[2:])
In [ ]:
print("The ASCII character representation of the binary code 1001000 is:", chr(int('1001000', 2)))
In [ ]:
one_to_five = [1, 2, 3, 4, 5]
The word ‘list’ is usually reserved for an ordered set of elements. Some languages also have the concept of a ‘collection’ of (unordered) elements (in Python, this is known as a ‘set’).
In [2]:
kitchen_utilities = ["pot", "pan", "knives", "forks"] # Notice the hard brackets
print(kitchen_utilities[0]) # 0 for the first entry, use 1 or 2 for the other entries.
In [3]:
print(kitchen_utilities[1:3]) # 0 for the first entry, use 1 or 2 for the other entries.
Depending on the language, the power of lists ranges from great to humongous.
In [ ]:
# lists can contain any objects, including other lists...
a_crazy_list_in_python = ['one', 2, 3.0, one_to_five]
print(a_crazy_list_in_python)
The use of more advanced structures often enables efficient implementation of complex computations (such as signal-processing operations on large datasets). The types of data structures available are highly language-dependent, and using them becomes natural if and when the domain-specific problem calls for it. No need to learn something you won’t use, however...
When operating with real-world measurements of some physical process or phenomenon (MRI, EEG, DNA/protein microarrays, ...), each individual data point usually has a meaningful positional relationship to other points. For example, a voxel in an MR image shares a face with 6 neighbouring voxels. The data point of a single EEG channel acquired at time t is "to the left of" that acquired at time t+1. Column 563 of a microarray plate is associated with the expression level of gene AbC-123. Etc. The relationship between data points can be highly non-trivial and, most importantly, the processing tasks applied to the data both expect a particular structure and exploit it during computations.
Numerical computations on measurement data are often (in practice: always) performed on optimised data types known as arrays. Arrays are N-dimensional cartesian "blocks" of data, sampled along some dimension (space, time, frequency, gene/protein ID, subject ID, ...).
Vector is just a special name given for a 1-dimensional array. Common to all arrays, and the programming languages that implement them (Matlab, the NumPy-module in Python, ...), is that the data they contain are laid out efficiently in memory: data belonging to an array are stored in a cluster of memory, instead of being randomly spread out over all possible addresses. The (huge) advantage of this approach is that whenever the data is to be operated on, the CPU only needs to know where (in memory) the array starts, and what it's dimensions are; there is no time wasted on locating each element of the array before operating on them.
In [ ]:
import numpy as np
data = np.random.rand(10,10)
print(data.shape)
print(data)
print(data[4, 2])
In [ ]:
3 + 2
In [ ]:
Add together the numbers 3 and 2
In [ ]:
sum(3, 2) # this is tricky, we’ll return to it later
In [ ]:
3 + -2
In [ ]:
3 + 2 .
In [ ]:
3 +* 2
In [ ]:
3 ** 2
x and y. In math notation you can multiply x and y like this: xy. What happens if you try that in Python? Why?
In [6]:
cp=60
b=229
dc=0.4
sh=49
ad=3
print(cp*b*(1-dc) + sh + (cp-1)*ad)
In [ ]:
# code goes here
You've implemented an analysis for quantifying the "functional connectivity" between brain regions, based on fMRI scans. Your plan is to compute the connectivity of each voxel in the brain, to each other voxel. The image dimension is $128 \times 128 \times 50$ voxels. How long will your analysis take to run if the time required for a single voxel is just 1 second?
In [ ]:
nof_voxels = 128*128*50
time_per_voxel = 1 # seconds
seconds_per_day = 60 * 60 * 24
time_in_days = # write expression here!
print('Come back in', time_in_days, 'days')
In situations like these, a combination of re-thinking the problem (domain knowledge) and optimising the implementation (e.g. using array containers for the data) is usually called for.
In [ ]:
# code goes here
The following example is shamelessly ripped off from this source.
Let's assume you work with human genome data. Even an engineer knows that the genome consists of four "bases": A, C, T and G. Four is a great number: 1-4 can be represented (encoded) using just two bits, for example: A=00, C=01, T=10 and G=11. Assuming the genome consists of a sequence of 3 billion letters, how many million bytes do we need to represent them all?
In [ ]:
nof_bases = 3000000000 # better: 3e9
bits_per_base = 2
megabytes_in_bits = 1024 * 1024 * 8
genome_size_MB =
print('Raw genome size:', genome_size_MB, 'MB')
A "clean" genome would thus fit into the memory of your laptop, but only just, and you wouldn't have much memory left to operate on it. However, in reality things are a lot worse than that, since real experimental data coming off sequencers are anything but "clean"! To get stable readings off the samples used, sequencers intentionally over-sample the genome by a large factor, as well as including quality-control meta-information in the data files created. The raw sequencing data for a single genome can be as large as 200 GB. Can you fit that into your laptop memory?
{kind=link}