최빈값은 빈도수가 가장 많이 발생한 관찰값을 말함
중앙값은 수치로 된 자료를 크기순서대로 나열할 때, 가장 가운데에 위치하는 관찰값을 말한다.
우리가 흔히 사용하는 간단한 평균, 그냥 "평균" 이라고도 한다.
$$\bar{X} = \frac{X_1 + X_2 + \cdots + X_n}{n} = \frac{\sum X_i}{n} $$같은 모집단에서 표본을 서로 다른 개수로 뽑은 경우(가중치가 존재하는 경우) 평균값을 구할때 사용
$$\bar{X} = \frac{n_1 \bar{X_1} + n_2 \bar{X_2} + \cdots + n_k \bar{X_k}}{n_1 + n_2 + \cdots + n_k} = \frac{\sum n_i \bar{X_i}}{n_i} $$: 관찰값들이 어느 쪽으로 치우쳐 있는가를 알아보는 척도
: 분포의 모양이 대칭분포에서 얼마나 벗어났는가
In [1]:
import numpy as np
np.random.seed(0)
data = np.random.randint(40, 100, size=(5, 5))
data
Out[1]:
In [2]:
data.mean()
Out[2]:
In [3]:
data.std()
Out[3]:
In [4]:
# X - mean
dev_arr = data - data.mean()
dev_arr
Out[4]:
In [5]:
# ( X - mean )^2
dev_arr ** 2
Out[5]:
In [6]:
# sum( ( X - mean )^2 ) / N
a = (dev_arr ** 2 ).sum() / 25
a
Out[6]:
In [7]:
np.sqrt(a)
Out[7]:
{kind=link}
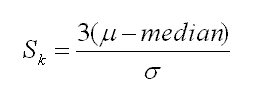{kind=link}