This notebook is supplemental material for a blog post I wrote (i.e., Uncovering Big Bias with Big Data). If you haven't read it, please take a moment and start there.
If you're new to notebooks, check out this quick start guide. Also, I've tried to provide useful links for people new to this sort of thing throughout.
UPDATE: The Lawyerist piece was written as a vehicle for introducing attorneys to regression analysis. Consequently, I made modeling choices informed by an attempt to maximize ease of understanding on the part of my audience while minimizing complaints from experts. As you can imagine, that's a hard balance. The overwhelming majority of comments and critiques were thoughtful, and most of them quite correct as suggestions for improving the model's predictive power. A sampling of the most frequent include: Why didn't you treat seriousness levels as categorical variables? What about collinearity? Shouldn't you include defendants' past criminal history? You call that cross-validation?
Fair or not, transparency (in the form of this notebook) was my primary relief value, inviting others to pick up where I left off and improve on the model. There's a reason I made such a fuss in the piece about the model not being a good predictive model, and why I pushed the George Box quote so hard. In short, the complexity that full examinations of the above and similar suggestions would have added to the piece would have likely lost my intended audience, and I'm not convinced such additional detail would have added much for said audience. At it's heart, the model presented is a discussion starter, "It’s important to note what we’re doing is modeling for insight. I don’t expect that we’ll use our model to predict the future. Rather, we’re trying to figure out how things interact. We want to know what happens to outcomes when we vary defendant demographics, specifically their race or income. The exact numbers aren’t as important as the general trends and how they compare... there’s a lot more one could do with this data..."
That being said, my hope is to find the time to revisit this dataset with an eye towards a different audience. Namely, one that will allow me to further explore the nuances in the data and address the issues raised by those readers looking for more robust analysis.
These are libraries we'll need to conduct our analysis.
In [1]:
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import pandas as pd
import seaborn as sns
from statsmodels.formula.api import ols
import statsmodels.api as sm
from IPython.display import Image
All of our court data will be coming from here: VA Court Data, maintained by Ben Schoenfeld (@oilytheotter). As the blog post makes clear, we'll be restricting our analysis to 2006-2010. So we'll start by loading data for that timeframe.
FYI, you'll notice that I'm referencing a directory not contained in this repo (i.e., ../data/). I did this so I don't have to worry about any of the issues that come with hosting such data in a publicly accessable repository. See note on data privacy.
In [2]:
# read in data
list_ = []
i = 0
yr = 2006
while yr <= 2010:
k = 0
while k < 12:
k += 1
#print ("loading: ../data/criminal_circuit_court_cases_%s/criminal_circuit_court_cases_%s_%s.csv"%(yr,yr,k))
list_.append(pd.read_csv("../data/criminal_circuit_court_cases_%s/criminal_circuit_court_cases_%s_%s.csv"%(yr,yr,k), low_memory=False))
i += 1
yr += 1
charges_df = pd.concat(list_)
# display first 4 rows
# charges_df[:4]
The reason we're focused on 2006-2010 is that we can use defendant zip codes to join our court data with American Community Survey (ACS) data on income. So below we'll pull out defendant zip codes and place them in their own column. To do this we use some magic known as regular expressions.
In [3]:
# Pull out zipcode to match with census data
charges_df['Zip'] = charges_df['Address'].str.extract('([0-9]*$)', expand=False)
# drop charges where zip can't be found
charges_df = charges_df[pd.notnull(charges_df['Zip'])]
# Make sure the zip is a number
charges_df['Zip'] = pd.to_numeric(charges_df['Zip'])
# fill in NaN (blank cells) to ease later work
charges_df = charges_df.fillna(value="")
# print new count
So now we need that income data. I found a nice spreadsheet with it over here: Zip Code Characteristics. Note the file MedianZIP-3.xlsx actually contained both mean and media values. Anywho, I downloaded the spreadsheet and saved it as a .csv called zip_income.csv. Then I cleaned it up a bit.
In [4]:
# Load the csv file into a dataframe
zip_df = pd.read_csv("../data/zip_income.csv")
# There were commas in the data. So let's strip those out.
zip_df['Median'] = zip_df['Median'].str.replace(',', '')
zip_df['Mean'] = zip_df['Mean'].str.replace(',', '')
# Also, we won't need the population column. So let's drop that too.
zip_df = zip_df.drop('Pop', 1)
# Exclude zip codes not in VA see http://www.zipcodestogo.com/Virginia/
zip_df = zip_df[zip_df['Zip']>=20101]
zip_df = zip_df[zip_df['Zip']!=23909] # note there was an error in this entry so I had to remove it
zip_df = zip_df[zip_df['Zip']<=26886]
zip_df['Mean'] = pd.to_numeric(zip_df['Mean'])
zip_df['Median'] = pd.to_numeric(zip_df['Median'])
# display first 4 rows
zip_df[:4]
Out[4]:
So now we need to construct some features. Again, the blog post has more context. Note, here are some explinations of charge types: Virginia Misdemeanor Crimes by Class and Sentences and Virginia Felony Crimes by Class and Sentences. Also, if you're unfamiliar with the idea of joins here's a primer with visuals. It's talking about SQL, but the concept holds.
In [11]:
# merge original data set and ACS data. THis is a join
munged_df = pd.merge(charges_df,zip_df,how='inner',on='Zip')
#
# NOTE: THE ORIGINAL VERSION OF THIS NOTEBOOK NEGLECTED TO REMOVE ENTERIES
# WITH UNIDENTIFIED RACE AND SEX COLUMNS. THE FOLLOWING LINES CORRECT THIS.
#
munged_df = munged_df[munged_df['Race'] != '']
munged_df = munged_df[munged_df['Sex'] != '']
# Translate charge types into positions on an ordered list from 1 and 10
munged_df['Seriousness'] = 0
munged_df.loc[(munged_df['ChargeType'].str.contains('Misdemeanor',case=False)==True) & (munged_df['Class'].str.contains('1',case=False)==True), 'Seriousness'] = 4
munged_df.loc[(munged_df['ChargeType'].str.contains('Misdemeanor',case=False)==True) & (munged_df['Class'].str.contains('2',case=False)==True), 'Seriousness'] = 3
munged_df.loc[(munged_df['ChargeType'].str.contains('Misdemeanor',case=False)==True) & (munged_df['Class'].str.contains('3',case=False)==True), 'Seriousness'] = 2
munged_df.loc[(munged_df['ChargeType'].str.contains('Misdemeanor',case=False)==True) & (munged_df['Class'].str.contains('4',case=False)==True), 'Seriousness'] = 1
munged_df.loc[(munged_df['ChargeType'].str.contains('Felony',case=False)==True) & (munged_df['Class'].str.contains('1',case=False)==True), 'Seriousness'] = 10
munged_df.loc[(munged_df['ChargeType'].str.contains('Felony',case=False)==True) & (munged_df['Class'].str.contains('2',case=False)==True), 'Seriousness'] = 9
munged_df.loc[(munged_df['ChargeType'].str.contains('Felony',case=False)==True) & (munged_df['Class'].str.contains('3',case=False)==True), 'Seriousness'] = 8
munged_df.loc[(munged_df['ChargeType'].str.contains('Felony',case=False)==True) & (munged_df['Class'].str.contains('4',case=False)==True), 'Seriousness'] = 7
munged_df.loc[(munged_df['ChargeType'].str.contains('Felony',case=False)==True) & (munged_df['Class'].str.contains('5',case=False)==True), 'Seriousness'] = 6
munged_df.loc[(munged_df['ChargeType'].str.contains('Felony',case=False)==True) & (munged_df['Class'].str.contains('6',case=False)==True), 'Seriousness'] = 5
munged_df = munged_df[munged_df['Seriousness'] > 0]
# Break out each race category so they can be considered by the linear regression
munged_df['Male'] = 0
munged_df.loc[munged_df['Sex'] == 'Male', 'Male'] = 1
munged_df['Native'] = 0
munged_df.loc[munged_df['Race'].str.contains('american',case=False)==True, 'Native'] = 1
munged_df['Asian'] = 0
munged_df.loc[munged_df['Race'].str.contains('asian',case=False)==True, 'Asian'] = 1
munged_df['Black'] = 0
munged_df.loc[munged_df['Race'].str.contains('black',case=False)==True, 'Black'] = 1
munged_df['Hispanic'] = 0
munged_df.loc[munged_df['Race'] == 'Hispanic', 'Hispanic'] = 1
munged_df['Other'] = 0
munged_df.loc[munged_df['Race'].str.contains('other',case=False)==True, 'Other'] = 1
# figure out what our sentece should be. Note: originally I was dooing more than renaming. So this is really some vestigle code.
munged_df['SentenceDays'] = pd.to_numeric(munged_df['SentenceTimeDays'])
munged_df['SentenceDays_T'] = np.log(1+munged_df['SentenceDays'])
munged_df = munged_df.fillna(value=0)
# partition data for cross-validation
holdout = munged_df.sample(frac=0.2)
training = munged_df.loc[~munged_df.index.isin(holdout.index)]
# optional print to file
munged_df.to_csv(path_or_buf='../data/output.csv')
#output_sample = munged_df[(munged_df['Seriousness'] <= 2) & (munged_df['SentenceDays'] > 0)]
#output_sample = munged_df.sample(n=5000)
#output_sample.to_csv(path_or_buf='../data/output_sample.csv')
# display first four rows
munged_df[:4]
Out[11]:
If you're not familiar with linear regressions, read the blog post then check out this: Introduction to Linear Regression.
In [6]:
# Run a simple linear regression & print the P values
model = ols("SentenceDays ~ Seriousness", training).fit()
print("P-values:\n%s"%model.pvalues)
# Plot regression
fig = sns.lmplot(x="Seriousness", y="SentenceDays", data=munged_df, scatter_kws={"s": 20, "alpha": 0.25}, order=1)
plt.rc('font', family='serif', monospace='Courier') # http://matplotlib.org/users/usetex.html
plt.title("Linear Regression\n(All Data Points)", fontsize = 17, y=1.05)
plt.xlabel('Seriousness')
plt.ylabel('Sentence in Days')
plt.annotate('R-squared: %f'%(model.rsquared), (0,0), (0,-45), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig('../data/tmp/f1.1.png',bbox_inches='tight');
In [9]:
# Run a simple linear regression & print the P values
model = ols("SentenceDays ~ Seriousness", training).fit()
print("P-values:\n%s"%model.pvalues)
# Plot Regression with estimator
fig = sns.lmplot(x="Seriousness", y="SentenceDays", data=munged_df, x_estimator=np.mean, order=1)
plt.rc('font', family='serif', monospace='Courier') #http://matplotlib.org/users/usetex.html
plt.title("Linear Regression\n(Representative \"Dots\")", fontsize = 17, y=1.05)
plt.xlabel('Seriousness')
plt.ylabel('Sentence in Days')
plt.annotate('R-squared: %f'%(model.rsquared), (0,0), (0,-45), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig('../data/tmp/f1.2.png',bbox_inches='tight');
In [9]:
# Run a simple linear regression & print the P values
model = ols("SentenceDays ~ Seriousness + np.power(Seriousness, 2)", training).fit()
print("P-values:\n%s"%model.pvalues)
# Plot multiple subplot axes with seaborn
# h/t https://gist.github.com/JohnGriffiths/8605267
fig_outfile = '../data/tmp/fig_1.3.png'
# Plot the figs and save to temp files
fig = sns.lmplot(x="Seriousness", y="SentenceDays", data=munged_df, x_estimator=np.mean, order=2);
fig = (fig.set_axis_labels("Seriousness", "Sentence in Days"))
plt.suptitle("2nd Order Polynomial Regression\n(Representative \"Dots\")", fontsize = 13, y=1.07)
plt.annotate('R-squared: %f'%(model.rsquared), (0,0), (0,-45), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig('../data/tmp/f1.3.1.png',bbox_inches='tight'); plt.close()
model = ols("SentenceDays ~ Seriousness + np.power(Seriousness, 2) + np.power(Seriousness, 3)+ np.power(Seriousness, 4)", munged_df).fit()
print("P values:\n%s"%model.pvalues)
fig = sns.lmplot(x="Seriousness", y="SentenceDays", data=munged_df, x_estimator=np.mean, order=4);
fig = (fig.set_axis_labels("Seriousness", "Sentence in Days"))
plt.suptitle("4th Order Polynomial Regression\n(Representative \"Dots\")", fontsize = 13, y=1.07)
plt.annotate('R-squared: %f'%(model.rsquared), (0,0), (0,-45), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig('../data/tmp/f1.3.2.png',bbox_inches='tight'); plt.close()
# Combine them with imshows
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12,6))
for a in [1,2]: ax[a-1].imshow(plt.imread('../data/tmp/f1.3.%s.png' %a)); ax[a-1].axis('off')
plt.tight_layout(); plt.savefig(fig_outfile,bbox_inches='tight'); plt.close()
# Display in notebook as an image
Image(fig_outfile, width="100%")
Out[9]:
In [10]:
# Run a simple linear regression & print the P values
model = ols("SentenceDays_T ~ Seriousness", training).fit()
print("P-values:\n%s"%model.pvalues)
# Plot multiple subplot axes with seaborn
# h/t https://gist.github.com/JohnGriffiths/8605267
fig_outfile = '../data/tmp/fig_2.png'
# Plot the figs and save to temp files
fig = sns.lmplot(x="Seriousness", y="SentenceDays_T", data=munged_df, scatter_kws={"s": 20, "alpha": 0.25}, order=1);
fig = (fig.set_axis_labels("Seriousness", "log(1 + Sentence in Days)"))
plt.suptitle("(All Data Points)", fontsize = 14, y=1.03)
plt.savefig('../data/tmp/f2.1.png',bbox_inches='tight'); plt.close()
fig = sns.lmplot(x="Seriousness", y="SentenceDays_T", data=munged_df, x_estimator=np.mean, order=1);
fig = (fig.set_axis_labels("Seriousness", "log(1 + Sentence in Days)"))
plt.suptitle("(Representative \"Dots\")", fontsize = 14, y=1.03)
plt.savefig('../data/tmp/f2.2.png',bbox_inches='tight'); plt.close()
# Combine them with imshows
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12,6))
for a in [1,2]: ax[a-1].imshow(plt.imread('../data/tmp/f2.%s.png' %a)); ax[a-1].axis('off')
plt.suptitle("Log-Linear Regression", fontsize = 17, y=1.02)
plt.tight_layout();
plt.annotate('R-squared: %f'%(model.rsquared), (-1.05,0), (0,-10), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig(fig_outfile,bbox_inches='tight'); plt.close()
# Display in notebook as an image
Image(fig_outfile, width="100%")
Out[10]:
In [11]:
# Run a simple linear regression & print the P values
model = ols("SentenceDays_T ~ Seriousness + np.power(Seriousness, 2)", training).fit()
print("P-values:\n%s"%model.pvalues)
# Plot multiple subplot axes with seaborn
# h/t https://gist.github.com/JohnGriffiths/8605267
fig_outfile = '../data/tmp/fig_3.png'
# Plot the figs and save to temp files
fig = sns.lmplot(x="Seriousness", y="SentenceDays_T", data=munged_df, x_estimator=np.mean, order=2);
fig = (fig.set_axis_labels("Seriousness", "log(1 + Sentence in Days)"))
plt.suptitle("2nd Order Polynomial Regression\n(Representative \"Dots\")", fontsize = 13, y=1.07)
plt.annotate('R-squared: %f'%(model.rsquared), (0,0), (0,-45), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig('../data/tmp/f3.1.png',bbox_inches='tight'); plt.close()
model = ols("SentenceDays_T ~ Seriousness + np.power(Seriousness, 2) + np.power(Seriousness, 3)+ np.power(Seriousness, 4)", munged_df).fit()
fig = sns.lmplot(x="Seriousness", y="SentenceDays_T", data=munged_df, x_estimator=np.mean, order=4);
fig = (fig.set_axis_labels("Seriousness", "log(1 + Sentence in Days)"))
plt.suptitle("4th Order Polynomial Regression\n(Representative \"Dots\")", fontsize = 13, y=1.07)
plt.annotate('R-squared: %f'%(model.rsquared), (0,0), (0,-45), fontsize = 11, xycoords='axes fraction', textcoords='offset points', va='top')
plt.savefig('../data/tmp/f3.2.png',bbox_inches='tight'); plt.close()
# Combine them with imshows
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12,6))
for a in [1,2]: ax[a-1].imshow(plt.imread('../data/tmp/f3.%s.png' %a)); ax[a-1].axis('off')
plt.tight_layout(); plt.savefig(fig_outfile,bbox_inches='tight'); plt.close()
# Display in notebook as an image
Image(fig_outfile, width="100%")
Out[11]:
In [12]:
# Plot multiple linear regression
# h/t https://www.datarobot.com/blog/multiple-regression-using-statsmodels/#appendix
from mpl_toolkits.mplot3d import Axes3D
X = training[['Seriousness', 'Mean']]
y = training['SentenceDays_T']
## fit a OLS model
X = sm.add_constant(X)
est = sm.OLS(y, X).fit()
## Create the 3d plot
xx1, xx2 = np.meshgrid(np.linspace(X.Seriousness.min(), X.Seriousness.max(), 100),
np.linspace(X.Mean.min(), X.Mean.max(), 100))
# plot the hyperplane by evaluating the parameters on the grid
Z = est.params[0] + est.params[1] * xx1 + est.params[2] * xx2
# create matplotlib 3d axes
fig = plt.figure(figsize=(12, 8))
ax = Axes3D(fig, azim=-120, elev=15)
# plot hyperplane
surf = ax.plot_surface(xx1, xx2, Z, cmap=plt.cm.RdBu_r, alpha=0.6, linewidth=0)
# plot data points
resid = y - est.predict(X)
ax.scatter(X[resid >= 0].Seriousness, X[resid >= 0].Mean, y[resid >= 0], color='black', alpha=0.25, facecolor='white')
ax.scatter(X[resid < 0].Seriousness, X[resid < 0].Mean, y[resid < 0], color='black', alpha=0.25)
# set axis labels
ax.set_title('Multiple Log-Linear Regression', fontsize = 20)
ax.set_xlabel('Seriousness')
ax.set_ylabel('Mean Income')
ax.set_zlabel('log(1 + Sentence in Days)')
Out[12]:
So the code below doesn't really capture how I go about cross-validation, but as a supplement to the blog post, I wanted to provide a look at how one might compare multiple models. Below you'll see summary statistics from sets of different regressions run both on the training and holdout data. A good description of the summary statistics can be found in this article: Linear Regressuib with Python.
You'll also notice a graph associated with each regression. These are residual plots, and the folowing article should help you understand how to read them. Interpreting residual plots to improve your regression.
In [12]:
print("========================")
print(" LINEAR")
print("========================")
model = ols("SentenceDays ~ Seriousness + Male + Mean + Black + Hispanic + Asian + Native + Other", training).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
model = ols("SentenceDays ~ Seriousness + Male + Mean + Black + Hispanic + Asian + Native + Other", holdout).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
print("========================")
print(" 2ND ORDER")
print("========================")
model = ols("SentenceDays ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", training).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
model = ols("SentenceDays ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", holdout).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
print("========================")
print(" 4TH ORDER")
print("========================")
model = ols("SentenceDays ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", training).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
model = ols("SentenceDays ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", holdout).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
print("========================")
print(" LOG-LINEAR")
print("========================")
model = ols("np.log(1+SentenceDays) ~ Seriousness + Male + Mean + Black + Hispanic + Asian + Native + Other", training).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
model = ols("np.log(1+SentenceDays) ~ Seriousness + Male + Mean + Black + Hispanic + Asian + Native + Other", holdout).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
print("========================")
print(" 2ND ORDER LOG-LINEAR")
print("========================")
model = ols("np.log(1+SentenceDays) ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", training).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
model = ols("np.log(1+SentenceDays) ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", holdout).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
print("========================")
print(" 4TH ORDER LOG-LINEAR")
print("========================")
model = ols("np.log(1+SentenceDays) ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", training).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
model = ols("np.log(1+SentenceDays) ~ Seriousness + np.power(Seriousness, 2) + Male + Mean + Black + Hispanic + Asian + Native + Other", holdout).fit()
print(model.summary())
plt.scatter(model.fittedvalues,model.resid,alpha=0.25)
plt.xlabel('perdicted')
plt.ylabel('residuals')
plt.show()
In the blog post I make use of a model to calculate how much money a person of color would need to earn in order to counteract race-base bias with class-based favor. The model below is the one I used. I opted to go with a log-linear model. This is in part because of its simplicity. As the post makes clear, I only need the model to be good enough to answer the question I'm asking (i.e., which is a bigger problem for the criminal justice system, race or class based bias?). And it has to be easily to explain the model to a general audience. That being said, this doesn't have to be the final word. Please take this work and expand on it. Just let me know how it goes.
Anywho, you'll notice that this model doesn't have the highest R-squared of the set. That's because I liked its residual plot better than the linear models with better R-squareds. As for the choice not to fit a polynomial, I didn't feel like I had very good theory to support such agressive fitting, and again, I'm just looking for an answer to my question, not a predictive model. That is, I'm modeling for insight. So I have a high tolerance for minor differences.
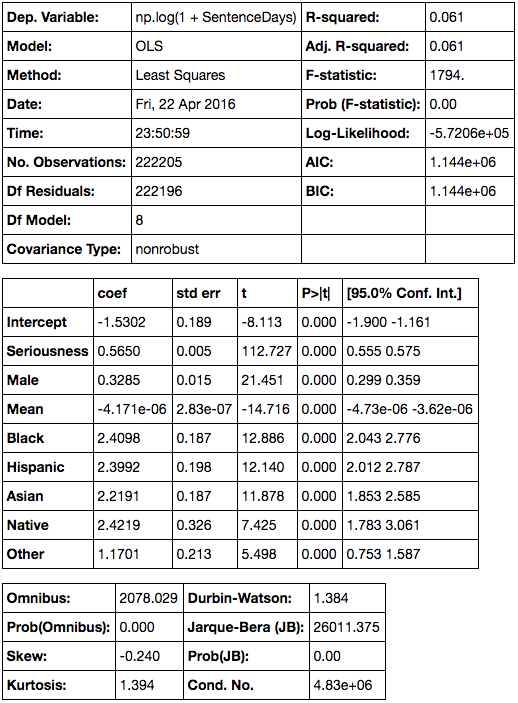
NOTE: an earlier version of this notebook neglected to remove enteries with unidentified race and sex. This issue has been corrected. However, it led the author to incorectly state the relative weights of the model's features. The corrected output is below. However, the old/incorrect summary statistics can still be found here and in this notebook's history.
In [15]:
model = ols("np.log(1+SentenceDays) ~ Seriousness + Male + Mean + Black + Hispanic + Asian + Native + Other", munged_df).fit()
#model = ols("np.log(1+SentenceDays) ~ Seriousness + Male + Mean + C(Race,Treatment(reference='White Caucasian (Non-Hispanic)'))", munged_df).fit()
model.summary()
Out[15]:
Here's the above model translated into an equation.
Note: if you're viewing this on GitHub, there seems to be a bug with thier equation formating. So if things look odd, that's why.
Where:
For income’s influence to counteract that of being black $\beta_3 x_3 + \beta_3 x_4 = 0$
Therefore:
$$ –0.000004166x+(0.3763)(1)=0 $$$$ x=\frac{0.3763}{0.000004166} $$$$ x=\$90,326.45 $$That is:
For a black man in a Virginia court to get the same treatment as his Caucasian peer, he needs to earn an additional $90,000 a year.
Similar amounts hold for American Indians and Hispanics.
In [ ]:
{kind=link}